Algorithmic Idealism: What Should You Believe to Experience Next?
Updated and modified from the peer-reviewed and published version in Found. Phys. 56, 11 (2026). DOI:10.1007/s10701-026-00913-1, arXiv:2412.02826.
Abstract
I argue for an approach to the Foundations of Physics that puts the question in the title center stage, rather than asking “what is the case in the world?”. This approach, algorithmic idealism, attempts to give a mathematically rigorous in-principle answer to this question both in the usual empirical regime of physics and in some more exotic regimes within cosmology, philosophy, and science fiction (but soon perhaps real) technology. I begin by arguing that quantum theory, in its actual practice and in some interpretations, should be understood as telling an agent what they should expect to observe next (rather than what is the case), and that the difficulty of answering this former question from the usual “external” perspective is at the heart of persistent enigmas such as the Boltzmann brain problem, extended Wigner’s friend scenarios, Parfit’s teletransportation paradox, or our understanding of the simulation hypothesis. Algorithmic idealism is a conceptual framework, based on two postulates that admit several possible mathematical formalizations, cast in the language of algorithmic information theory. Here I give a non-technical description of this view and show how it dissolves the aforementioned enigmas: for example, it claims that you should never bet on being a Boltzmann brain, regardless of how many there are, that shutting down computer simulations does not generally terminate its inhabitants, and it predicts the apparent embedding into an objective external world as an approximate description.
Table of Contents
- Prologue: When The World is Not Enough
- Quantum Probabilities as Objective Degrees of Epistemic Justification
- Restriction A: Physics Does Not Always Tell Agents What They Should Believe
- Algorithmic Idealism in a Nutshell
- Algorithmic Information Theory and the Bit Model
- Predictions of Algorithmic idealism
- Example: How to Think About the Simulation Hypothesis
- Conclusions
- Acknowledgments
- References
1. Prologue: When the World is Not Enough
It is the year 2048. You can no longer feel your arms and legs, but you dream of the warm autumn sun breaking through colorful leaves. A blackbird calls from a distance and your daughter smiles at you, a picnic blanket, the shade of the trees. Only the flickering of the ceiling light and the flashing of the surveillance monitors bring you back to reality, and only temporarily, until the warm feeling of the pain medication makes your perception fade.


You are terminally ill. You only have a few days to live, at least that’s what the Doctor says. And yet this realization, in the bright moments between the effects of the morphine and drifting off to sleep, does not fill you with despair: you have taken precautions. Two years ago you signed a contract with AfterMath Ltd.: shortly after your death you will be scanned1This story and most of what follows assumes that agents (at least the ones we mean here, which is ultimately supposed to include humans) can in principle be described classically, and potentially with a finite amount of classical information. This is compatible with the fact that some biological processes are genuinely quantum-mechanical and / or continuous, but a possible intuition is that these details must ultimately be irrelevant for all that matters for us as persons (including conscious experience), since robust functioning seems to forbid dependence on too fine-grained details. Whether this assumption is well-justified is the subject of contemporary debate, with a vast body of literature on e.g. the (un)suitability of “mind uploading”. For a recent proposal against this assumption, claiming that quantum states are at the heart of consciousness, see e.g. G. M. D’Ariano and F. Faggin, Hard Problem and Free Will: An Information-Theoretical Approach, in Scardigli, F. (ed.), Artificial Intelligence Versus Natural Intelligence, Springer, Cham, 2022; arXiv:2012.06580 by a team of specially trained neuroscientists with a particular machine, and your body will be destroyed in the process. A few days later, you will be digitally resurrected in a simulated world on a computer.
You have not made this decision lightly. You have spent years studying philosophy, ethics and neuroscience. In the end, it was thoughts like Bostrom’s fable2N. Bostrom, The Fable of the Dragon-Tyrant, J. Med. Ethics 31, 273-277 (2005); copy on Bostrom’s homepage. and the experimental results of AfterMath that convinced you to go for it. You are pretty sure that you are trying the right thing. And you are hopeful that it will go well.
And yet, you are afraid. You are afraid because you are human. The perception fades, the pain disappears, but the fear and the will to live remain. Your eyes are closed, but you feel the Doctor enter the room. You must have heard his feet scrubbing across the plastic floor of the hospital room, albeit unconsciously.
You clear your throat. At first you can’t get a word out, but then you manage to whisper quietly.
You: “Doctor, I’m so scared…” (coughing) “I know this is not your specialty, but… I need to know! Will I really wake up in the computer simulation?”
You instantly regret having asked, because you know the doctor very well. The doctor is a former physicist, not only a physician, but a physicalist by conviction. He is excellent in his job, but you don’t remember him as particularly empathetic.
Doctor: “Hahaha, you fool! You are asking a non-question! All there is to say is that there is a human being here now, and a computer running a simulation of that thing later. This is all there is to know about the facts of the world.”
The Doctor goes on to refill your infusion. “You’ve paid AfterMath to run that computer simulation, and this is what is going to happen. I don’t even understand what you are actually uncertain about? You know exactly what will be the case in the world!”
| Further resources • Earlier technical paper with all proofs: MPM, Quantum 4, 301 (2020), and a slightly outdated talk video as of 2021. • Recent paper motivating a.id. via “Restriction A” as arising in Wigner’s friend, duplication, ++: C. L. Jones and MPM, Quantum 10, 2147 (2026), and slides of a talk at the University of London, 2025. |
FAQ & clarifications
Q1: Is this an interpretation of quantum mechanics?
A: No. It is a mathematically rigorous, but radical and counterintuitive approach to physical reality more generally. It is strongly motivated by quantum mechanics, but it is a separate theory which aims at making concrete predictions for some scenarios that we do not yet understand.
Q2: What kinds of concrete predictions?
A: Probabilistic predictions for experiments that can be precisely specified, but not necessarily intersubjectively verified. Science is typically concerned with experiments whose results can be seen and analyzed by everybody (the grey area in the picture), and algorithmic idealism’s goal is to extend this regime of applicability to all fundamental physics experiments, including “private” ones.
Science is typically concerned with experiments whose results can be seen and analyzed by everybody (the grey area in the picture), and algorithmic idealism’s goal is to extend this regime of applicability to all fundamental physics experiments, including “private” ones.
Q3: This doesn’t sound like science! What are predictions worth if nobody can check them?
A: The goal is to have a single theory that makes both types of predictions — ones that can be intersubjectively verified, and ones that cannot. If the collectively verifiable “standard” predictions work out fine, then this is evidence for the correctness of the more exotic, private predictions.
2. Quantum Probabilities as Objective Degrees of Epistemic Justification
We usually think that physics is the science of what the world is like. The idea that the contents of our physical theories represent actual things in the world, and that these things have properties that exist objectively and independently of any observer, is a characteristic assumption of many versions of scientific realism3A. Chakravartty, Scientific Realism, The Stanford Encyclopedia of Philosophy (Summer 2017 Edition), Edward N. Zalta (ed.).. And there are good reasons to be a scientific realist: for example, realism allows us to understand that the success of science is not a miracle, but due to the fact that our theories are at least approximately representative of the truth. Intuitively, rejecting realism seems dangerously close to irrationality and pseudoscience4A. Sokal and J. Bricmont, Fashionable Nonsense: Postmodern Intellectuals’ Abuse of Science, New York: Picador, 1999.. And yet, quantum physics challenges5To avoid potential misunderstandings from the outset, algorithmic idealism is not meant to be a new interpretation of quantum theory. It is a theory that aims to make concrete predictions in regimes where they are currently lacking (“private experiments” as discussed in Section 3). In order to do so, it turns out necessary to set standard realist assumptions aside and focus exclusively on the question of the title of this paper. Quantum physics is seen as additional motivation for this focus. The goal is to construct the theory and explore its predictions (some of which are highly counterintuitive), not to have a detailed and philosophically exhaustive discussion of quantum theory, probability, or of all conceptual views that are articulated as motivation for it. at least the most naive versions of realism.
This is evident in the scientific practice of quantum physics. Imagine a particle that has been prepared in a superposition state of two paths in an interferometer. When we measure, we will find the particle in one of the branches, and not in the other. But what is the case before the measurement? A naive stipulation that the particle is in one of the branches, but we do not know which one, leads easily to contradictions with the actual statistics we observe in experiments6In more detail, a contradiction appears if we have a final beamsplitter that leads to perfect destructive interference, and if we naively model the experiment as a probability-1/2 mixture of the two experimental realizations where the particle is deterministically prepared in the upper or in the lower branch, respectively. It is simply a methodological observation that the most straightforward epistemic interpretations tend to fail to explain the experimental results. Making this simple methodological observation formally rigorous is important, but requires substantially more work, e.g. of proving that no noncontextual ontological model reproduces the specific functional form of the quantum uncertainty relations characteristic of the interference experiment, see e.g. L. Catani, M. Leifer, G. Scala, D. Schmid, and R. W. Spekkens, What is Nonclassical about Uncertainty Relations?, Phys. Rev. Lett. 129, 240401 (2022)..
We can certainly write down a wavefunction that describes all there is to say about the particle before the measurement, but as soon as we claim that the wavefunction represents “what is actually the case”, there appears a strange disconnect between the facts that we actually see (the concrete “classical” measurement outcomes) and those before we look (the quantum states). Wavefunctions do not satisfy our basic intuitions about how “facts of the world” should behave. For example, it is provably impossible to observe them directly7W. Wootters and W. Zurek, A Single Quantum Cannot be Cloned, Nature 299, 802–803 (1982).. If we think of the wave functions assigned by some observer as a real property of the physical system that it is supposed to describe, then it would seem to collapse nonlocally and instantaneously upon measurement, in potential tension with relativity (see e.g.8A. Peres, Quantum theory: concepts and methods, Kluwer Acad. Publ., Dordrecht, 2010. for more details)9These observations certainly do not rule out the possibility of realist interpretations of the quantum state. For example, Everettian interpretations evade the need for collapse, at the expense of distinguishing the absolute quantum state of the universe from the branch-relative quantum state assigned by an observer (H. Everett, The Theory of the Universal Wave Function, 1956, in B. S. DeWitt and N. Graham (eds.), The Many-Worlds Interpretation of Quantum Mechanics, Princeton University Press, Princeton, 1973). This is arguably a significant departure from our intuitive view on “facts of the world”. De Broglie-Bohm theory and objective collapse models are further examples of consistent realist interpretations, but whether they can be (or have been already) formulated in a way that avoids conflict with special relativity is subject to ongoing debate (D. Dürr, S. Goldstein, T. Norsen, W. Struyve, and N. Zanghì, Can Bohmian mechanics be made relativistic?, Proc. R. Soc. A 470, 20130699 (2014).; G. Ghirardi and A. Bassi, Collapse Theories, The Stanford Encyclopedia of Philosophy (Fall 2024 Edition), E. N. Zalta & U. Nodelman (eds.))..
Methodologically, this implies that quantum physics does not allow us to rely on our intuitions shaped by naive realism about how things in the world and their properties should behave. Now, the quantum foundations community has rightly pointed out that a lack of intuition, or of imagination, is insufficient to draw any direct metaphysical conclusions. Many phenomena that seem genuinely quantum, such as interference, entanglement, no-cloning, or teleportation, can be reproduced “classically”, i.e. by models based on classical variables that satisfy natural properties such as locality or noncontextuality10R. W. Spekkens, In defense of the epistemic view of quantum states: a toy theory, Phys. Rev. A 75, 032110 (2007); L. Hausmann, A consolidating review of Spekkens’ toy theory, arXiv:2105.03277; L. Catani, M. Leifer, D. Schmid, R. W. Spekkens, Why interference phenomena do not capture the essence of quantum theory, Quantum 7, 1119 (2023).. What is needed are no-go theorems that tell us that it is provably impossible to reproduce a phenomenon classically under such assumptions — but those results exist, and Bell’s theorem11J. S. Bell, On the Einstein Podolsky Rosen paradox, Physics 1, 195 (1964). is the most paradigmatic example of this. It implies that the correlations between spacelike separated events cannot always be explained by a classical common cause, i.e. by a classical hidden-variable model that respects the causal structure of the experimental setup12C. J. Wood and R. W. Spekkens, The lesson of causal discovery algorithms for quantum correlations: Causal explanations of Bell-inequality violations require fine-tuning, New J. Phys. 17, 033002 (2015).. Hence, our realist intuition that the local measurements simply uncover objective, preexisting facts of the world must go wrong, unless locality is violated. In scientific practice, it is then often a methodological move to give up on realist intuitions for quantum systems “in between” measurements.
Acknowledging the limitations of the received realist view becomes actually explanatorily powerful: it allows us, for example, to understand intuitively why “device-independent cryptography” works13J. Barrett, L. Hardy, A. Kent, No signaling and quantum key distribution, Phys. Rev. Lett. 95, 010503 (2005).; R. Colbeck, Quantum and Relativistic Protocols For Secure Multi-Party Computation, PhD Thesis, University of Cambridge, 2006.; S. Pironio, A. Acín, S. Massar, A. Boyer de la Giroday, D. N. Matsukevich, P. Maunz, S. Olmschenk, D. Hayes, L. Luo, T. A. Manning and C. Monroe, Random numbers certified by Bell’s theorem, Nature 464, 1021 (2010).. In this scheme, Alice and Bob perform measurements on two quantum systems that have been prepared in an entangled state, and observe a violation of a Bell inequality on many repetitions. Without any knowledge of the workings of their devices, this allows them in some cases to extract private random bits that are provably unpredictable by any adversary subject to the no-signalling principle. Intuitively, this is because the random bits have not been “facts of the world” before the measurements, and nobody can spy on non-existent bits.
The difficulty of saying what quantum states tell us about the world therefore invites us to shift the focus from the standard realist view towards a more empiricist perspective. We can focus on what quantum states definitely do tell us, according to the consensus of the practicing physicists: they tell us what we should expect to observe in an experiment. Given a specification of an experiment which implies a description of the involved quantum states and measurement operators, the Born rule tells us which probabilities to assign to the possible measurement outcomes. In a double-slit experiment, for example, it would be wrong to think that the quantum state tells us through which slit the particle is actually passing; but it tells us what to expect about the place at which we will observe the particle hitting the screen. In other words, quantum theory is about what we should believe to observe next.
This methodological diagnosis is compatible with many interpretations of quantum theory14This diagnosis is also compatible with QBism, even if the QBists would perhaps not like to phrase it in these terms. They would emphasize that the Born rule is a mere consistency requirement (see e.g. J. B. DeBrota, C. A. Fuchs, and R. Schack, Respecting One’s Fellow: QBism’s Analysis of Wigner’s Friend, Found. Phys. 50, 1859–1874 (2020)). between an agent’s personal assignments of the quantum state, the measurement operator, and the outcome probability. But this implies that any agent that has made up its mind about what quantum state and measurement operator to assign should hold beliefs about outcome probabilities that are given by the Born rule., since they all agree on how to practically use quantum theory successfully. But we can go one step further, and claim that this is actually what the quantum state is. This is the content of Berghofer’s degrees of epistemic justification interpretation (DEJI)15P. Berghofer, Quantum Probabilities Are Objective Degrees of Epistemic Justification, arXiv:2410.9175.: “In short, DEJI is an agent-centered interpretation that views quantum mechanics as a single-user theory that allows an experiencing subject to answer the following question: Based on my experiential input, what should I believe to experience next? The input is the wave function and the output is quantum probabilities.”
Berghofer’s interpretation16Berghofer’s interpretation and algorithmic idealism differ significantly: DEJI is an interpretation of quantum theory, and algorithmic idealism (a.id.) is not. Quantum theory matters for a.id. in two ways: first, as a motivation to focus on the question of what is observed next; and second, as a “litmus test” to see whether some quantum phenomena are predicted by a.id. However, a.id. is not an interpretation of an existing theory, but a new theory that intends to make novel predictions, as outlined in the next sections. A.id. benefits from the conceptually rigorous formulation of DEJI, which clarifies its own use of probability substantially. can be understood as a modification of QBism17F. A. Fuchs, Notwithstanding Bohr, the Reasons for QBism, Mind and Matter 15(2), 245-300 (2017); arXiv:1705.03484. (formerly known as Quantum Bayesianism), which views quantum states as subjective degrees of belief. However, given that quantum mechanics is our most successful and fundamental theory of physics, this raises the question of “how objectivity could enter science” in QBism18P. Berghofer, Quantum Probabilities Are Objective Degrees of Epistemic Justification, arXiv:2410.19175.. According to DEJI, quantum probabilities are objective degrees of epistemic justification. In this sense, quantum probabilities tell us something objective about the world: not what is the case in the world, but what we should expect Nature to answer if we ask it a question. In the rest of this paper, we will consider several exotic situations in which agents ask Nature a question. We are not interested in what agents believe, but what type of laws determines what they will actually probably receive as an answer — or, in other words, what they should believe to observe. Hence, Berghofer’s work will be our guiding interpretation when formulating such probabilistic laws.
Q4: Some concrete example predictions?
A: Depending on the concrete mathematical model, algorithmic idealism suggests e.g. an answer to the patient’s question in the story on the left: “will I wake up in the computer simulation?” The answer is probabilistic, and depends on the information-theoretic structure of the patient’s “self” and of the simulation. Algorithmic idealism also says that you should not believe to be a Boltzmann brain, regardless of how many there actually are in the universe, with implications for cosmology. It tells you what to believe under Parfit-like duplication scenarios, or what an Artificial Intelligence should believe when it is copied or duplicated. It says that simulated beings are not in general terminated when their simulation is shut down, for example.
Q5: Even if we are interested in making predictions for these far-out scenarios, why should I trust that this theory predicts correctly?
A: Because it predicts some things that we actually see. For example, in contrast to standard physics which simply assumes this, it predicts that agents will typically make observations that are as if they were embedded into an external world with algorithmically simple, probabilistic laws. Up to perhaps some choices of mathematical details, it is arguably the simplest possible extrapolation of the scientific method from the usual regime to the “far-out” regime.
Q6: In what sense is it an extrapolation of the scientific method to another regime?
A: Among other things, science takes observed data and uses a method of induction to predict future observations. Universal induction is a version of this method that can be mathematically formalized, based on algorithmic information theory. Under versions of the Church-Turing thesis, it makes provably correct physical predictions in the standard regime. Algorithmic idealism can be interpreted as the simple prescription: “Just assume that universal induction would in principle work in all regimes“.
Q7: Idealism is dead. It can never explain why there seems to be a lawlike external physical world.
A: Algorithmic idealism is not actually a form of idealism; it starts with a notion of “self” rather than “world” (hence the name), but does not fit nicely into the philosophical category. For example, it is not related to consciousness directly; most importantly, the existence of an external world governed by simple laws is not a miracle, but a prediction of algorithmic idealism. In this sense, it overcomes the arguably most serious problem of idealism.
3. Restriction A: Physics Does Not Always Tell Agents What They Should Believe
Berghofer’s interpretation is but one example of a broader class of “neo-Bohrian”19M. E. Cuffaro, The Measurement Problem Is a Feature, Not a Bug –Schematising the Observer and the Concept of an Open System on an Informational, or (Neo-)Bohrian, Approach, Entropy 25(10), 1410 (2023). interpretations, which include Healey’s pragmatism20R. Healey, Quantum Theory: a Pragmatist Approach, British J. Philos. Sci. 63(4), 729–771 (2012)., Brukner and Zeilinger’s21Č. Brukner and A. Zeilinger, Information and fundamental elements of the structure of quantum theory, arXiv:quant-ph/0212084. views, Bub’s information-theoretic interpretation22J. Bub, Bananaworld. Quantum Mechanics for Primates, Oxford University Press, Oxford, 2016., Rovelli’s relational interpretation23C. Rovelli, Relational Quantum Mechanics, Int. J. Theor. Phys. 35, 1637 (1996)., and others. The exact differences between these views, and how to best delineate them from other views and each other, are not relevant for the purpose of this paper. The conclusion that I argue to be drawn at this point is simply this: both scientific practice and a class of interpretations (most explicitly, Berghofer’s) suggest that quantum theory is best understood as telling an agent what they should believe to experience next.
It is not necessary to agree with any one of these interpretations to share the broadly empiricist sentiment that the question of “What will I see next?” is an epistemically more modest and perhaps more fruitful one than “What is really the case in the world?”. After all, the world might be a much weirder place than we have ever imagined, and humans have a bad track record of guessing the counterintuitive metaphysics of modern physics a priori. Methodologically, it makes sense to concentrate on the requirement that physics should allow us, at the very least, to make successful predictions. This includes predictions that can be intersubjectively verified, but also private ones that are in some sense irreducibly relative to an observer24Physical theories do not directly predict all intersubjectively communicable outcomes of experiments, but only those that are in some precise sense objectively definable; and similarly, algorithmic idealism does not aim for predictions of all outcomes of private experiments. For example, physics allows us to predict probabilistically whether we will hear a detector click, and algorithmic idealism says that we should be able to do the same even if the outcome is private (as in a duplication or Wigner’s friend type experiment). However, neither physics nor algorithmic idealism address directly questions of qualia, say, whether e.g. an agent will observe beauty or joy or be conscious next. We may certainly believe that these supervene on the precisely definable properties, but to understand how exactly this is the case might be so difficult to characterize that it may be a better strategy to consider the study of this question a different field of inquiry..
It may at first sight seem unlikely that there should be any relevant sought-for predictions of this “private” type, but here I will argue that there are in fact plenty, and that some of them are of utmost importance for physics, philosophy, and humanity at large. The question raised by the patient in Section 1 is an archetypical example of this. The answer to the patient’s question “Will I really wake up in the computer simulation?” can only be verified privately, not intersubjectively. That is, any claim of an answer cannot be empirically tested externally; say, by running the scanning and simulation process on a large number of people, and doing statistics about how many times the respective test person has actually woken up in the simulation. The answer to the question is by construction independent of any facts of the world25The problem here is much deeper than the use of indexicals per se. For example, the question of “Where am I?” can be rephrased as asking “Where is this particular patient [insert name and ID number, or some other unique external identifier] currently located?”, i.e. deindexicalized, and an answer can be derived from facts of the world. In Adlam’s terminology (see E. Adlam, Against Self-Location, arXiv:2409.05259), we can always use our beliefs about what is the case in the world to set our superficially self-locating credences, in contrast to pure self-locating credences which are subject to Restriction A. that any third-person view could discover26We can certainly imagine a (contrived) theory that claims, for example, that the patient will experience waking up in the simulation if and only if the temperature in the hospital room was less than 30∘C at the time of scanning. Then learning a third-person fact (the temperature) would tell us the answer to this first-person question, assuming that this theory is true. However, simply learning the temperature and inferring all consequences of this as predicted by our current physical theories, or as predicted by any other future physical theory that makes only intersubjectively verifiable claims, does not tell us anything about how to answer this question.. We can certainly ask the simulated person whether they feel like they have just woken up from the death bed, but the answer will unequivocally be “yes”, regardless of whether this has actually happened, or whether the actual patient has subjectively died and been replaced by a seemingly identical clone with implanted false memories.
A typical physicalist reaction to this question would be to deny that this is a meaningful distinction to be made in the first place: after all, there is no “fact of the world” that could ground the answer this question27The problem is not whether it would actually be possible to scan the human being and simulate it in a functionally equivalent way — as mentioned in the first footnote of this paper, here we always make the working assumption that it is. The point is rather that there is no meaningful question to be asked from a physicalist third-person perspective, as articulated by the Doctor in Section 1: the question “what will probably happen to me?” is not a question about facts of the world, as its answer is independent of any claims about e.g. how matter behaves.. The disadvantage of this reaction is that it robs us of any hope for guidance if we actually face this situation (like you did in Section 1), which might well be the case within the next century or so. Furthermore, as the Boltzmann brain (BB) example below will demonstrate, there are situations in physics where we have encountered questions of a similar type (such as “should I believe that I will make a BB-type observation next?”) whose answers cannot be grounded on facts of the world either (even though it may at first seem that they could).
Indeed, recent no-go theorems tell us that we cannot always ground our beliefs about our own future observations on expected objective properties of the world, unless we give up important principles such as locality28The locality assumption of Bong et al. (K.-W. Bong, A. Utreras-Alarcón, F. Gharafi, Y.-C. Liang, N. Tischler, E. G. Cavalcanti, G. J. Pryde, and H. M. Wiseman, A strong no-go theorem on the Wigner’s friend paradox, Nat. Phys. 16, 1199–1205 (2020)) is much weaker than the locality assumption in Bell’s theorem: it does not refer to hidden variables, but expresses no-signalling for actually observed outcomes (“the probability of an observable event is unchanged by conditioning on a space-like-separated free choice z, even if it is already conditioned on other events not in the future light-cone of z.”). This is necessary to avoid conflict with relativity.. Consider the thought experiment sketched in Figure 1 by Bong et al.29K.-W. Bong, A. Utreras-Alarcón, F. Gharafi, Y.-C. Liang, N. Tischler, E. G. Cavalcanti, G. J. Pryde, and H. M. Wiseman, A strong no-go theorem on the Wigner’s friend paradox, Nat. Phys. 16, 1199–1205 (2020)., which is a Wigner’s friend-type30E. P. Wigner, Remarks on the Mind-Body Question, in Symmetries and Reflections, 171–184, Indiana University Press, Bloomington, Indiana, 1967. scenario, but extended to involve four observers and an entangled quantum state. An external observer can repeat the experiment many times, and record the outcomes a and b of the agents Alice and Bob, given their choices of settings x and y. Doing so, this observer may determine a relative frequency estimate of the probabilities \( P(a,b|x,y) \), and compare the result with the quantum predictions. Assuming empirical adequacy of quantum theory, i.e. the correct prediction of the outcome probabilities of actually observed events in this scenario, Alice and Bob can use these quantum predictions to determine what they should believe to observe in this experiment: Alice should assign the probability $$ P(a,x)=P(a|x,y)=\sum_b P(a,b|x,y) $$ to seeing outcome a if she chooses setting x (the first equality is due to the no-signalling principle, since Alice and Bob are spacelike separated). A similar calculation applies to Bob. If we only consider Alice and Bob, then this resembles a very familiar story as we could also have told it in the context of, say, classical statistical mechanics: Alice can determine the probabilities she should assign to her own future observations by marginalization of the joint probability distribution over all relevant facts of the world at the moment of observation.

In quantum theory, we cannot always assign joint probability distributions to all variables that may, counterfactually, potentially be observed in the future, as Bell’s theorem demonstrates. However, we could have hoped that there is still a “classical” regime of the world where we can talk about variables in the usual sense that are jointly distributed, if we restrict our consideration to variables that are actually observed. Indeed, this is typically the case in our everyday world: all humans share a common Heisenberg cut, and everything that we observe during our lifetimes can (so far) be shared with all other humans. All observations (outcomes, experiences) are part of a large Boolean algebra of propositions, and we can think of a joint probability distribution that corresponds to what any hypothetical external observer should believe about the world. What we ought to believe about our future observations should then be derived from this as a marginal probability distribution, at least in principle (in practice we certainly use heuristic simplifications and shortcuts).
However, this situation will change as soon as we implement extended Wigner’s friend experiments such as the one described above in our world. In this case, the results above tell us that the observations a, b, c, d made by Alice, Bob, Charlie and Debbie, respectively, do not belong to a Boolean algebra of propositions of the type just described. That is, if the externally observed statistics \( P(a,b|x,y) \) violates a so-called local friendliness inequality, then there cannot for all x, y exist a joint probability distribution \( P(a,b,c,d|x,y) \) of the observations of all four observers from which \( P(a,b|x,y) \) derives, unless either the principle of locality or of no-superdeterminism (or both) are violated. But if there is no such distribution, then the four observers cannot all use the “standard methodology” to determine what they should expect to see in the experiment. That is, the four observers cannot start with what they believe about the facts of the world (including \( a \), \( b \), \( c \), \( d \)), and from this deduce their own small part of this (the marginal distribution on \( a \) and \( b \)). Depending on one’s interpretation of quantum theory, one might conclude that Charlie and Debbie can individually use the Born rule to obtain probabilities \( P(c) \) and \( P(d) \), but the validity of these assignments can never be verified externally.
In a recent publication32C. L. Jones and M. P. Müller, On the significance of Wigner’s Friend in contexts beyond quantum foundations, Quantum 10, 2147 (2026)., we have introduced some terminology that aims at describing the essential core of this observation:
Restriction A (informally): Our physical theories do not (and sometimes cannot) give us joint predictions for the future observations obtained by all agents.
More formally, Restriction A is a property of any given theory T (such as quantum theory, supplemented by additional assumptions such as locality and no-superdeterminism), and predictions are assumed to be formalized as probability distributions. Restriction A may apply to some scenarios (models, experiments) within T, but not others. It applies to N = 4 observers in the Wigner’s friend scenario above, and it applies to a single observer, i.e. N = 1, in the simulation scenario of Section 1.
The cases of N = 1 and N ≥ 2 have quite different interpretations. For N = 1 agent, Restriction A points at a deficiency of the given physical theory: the agent might want to predict its own future observations, but cannot. For N ≥ 2 agents, Restriction A says that the agent cannot obtain such predictions by predicting properties of the external world that are facts for all agents. We will return later to the question of how to interpret this.
Moreover, suppose that the theory T is intersubjectively empirically complete in the following sense: for all experiments for which the results can be recorded and shared among all external observers (not necessarily among all participants in the experiments, such as Charlie and Debbie), the theory T actually supplies us with a statistical prediction for this experiment. If this is the case, then Restriction A only applies to theory T in scenarios where the agent’s observations cannot be externally recorded; in other words, where there is some sort of “epistemic horizon”33J. Fankhauser, Epistemic Boundaries and Quantum Uncertainty: What Local Observers Can (Not) Predict, Quantum 8, 1518 (2024); J. Fankhauser, T. Gonda, and G. De les Coves, Epistemic Horizons From Deterministic Laws: Lessons From a Nomic Toy Theory, Synthese 205, 136 (2025); J. Szangolies, Epistemic Horizons and the Foundations of Quantum Mechanics, Found. Phys. 48, 1669 (2018). that separates some of the observers from some others. This is indeed the case in Bong et al.’s thought experiment: as we have already seen, it is impossible to record the outcomes a, b, c, d in every single run of the experiment, and to obtain statistics that can, say, be published in a scientific journal. The problem is that asking Charlie or Debbie for their outcomes will in general disturb the experiment, and will prevent the violation of a local friendliness inequality. Similarly, in the simulation scenario of Section 1, it was impossible for any third person (such as the Doctor) to even decide whether the event that the agent was wondering about has actually happened or not in any single implementation. After all, this was the reason for the Doctor to dismiss the patient’s question: a physicalist might want to claim that the third-person facts of the world are all there is to say, and the main characteristic of a “fact” is its intersubjective external accessibility.

In Ref.34C. L. Jones and M. P. Müller, On the significance of Wigner’s Friend in contexts beyond quantum foundations, Quantum 10, 2147 (2026)., we have explained in detail why we think that Restriction A is at the core of several other enigmas in the Foundations of Physics and Philosophy. Here I only briefly sketch two of them. The first puzzle is cosmology’s Boltzmann brain problem. For a thorough introduction, I refer the reader to Carroll’s work35S. M. Carroll, Why Boltzmann brains are bad, Current Controversies in Philosoph of Science, Routledge, 7–20 (2020), arXiv:1702.00850.; the following is an extremely brief and cartoonish summary. Suppose that we have a model of the universe that predicts it to be combinatorially large. In this case, thermodynamic fluctuations will produce all kinds of unlikely events in this universe, including Boltzmann brains: local collections of matter that, by mere chance, are functionally equivalent to a human brain, complete with false memories and thoughts such as “I have lived on Earth for 30 years”. Now, what if our cosmological model predicts that there are many more (of the order, say, 10100) Boltzmann brains than “ordinary” brains that have evolved on planets? An intuitive thought is that, in this case, we should expect to be Boltzmann brains. But Boltzmann brains would typically make some very unexpected observations soon (if they don’t disintegrate right away), such as seeing high-temperature radiation instead of the usual night sky. Since this is not what we observe (and we do not seem to disintegrate either), we seem to not be Boltzmann brains36As pointed out by Carroll (S. M. Carroll, Why Boltzmann brains are bad, Current Controversies in Philosoph of Science, Routledge, 7–20 (2020), arXiv:1702.00850), a more thorough and careful argumentation should revolve around the notion of cognitive instability: if a physical theory gives us reasons to believe that we are Boltzmann brains, then this theory undermines all reasons to trust its predictions in the first place.. Does this mean that we have just falsified the corresponding cosmological model?
It is important to note that cosmology, or our current physical theories more generally, only tell us (an estimate of) the number of Boltzmann brains and, perhaps, of ordinary brains, given some cosmological model. But they do not tell us what you should believe if you wonder whether you are one or the other — in particular, which probability you should assign to making an extraordinary Boltzmann-brain-type observation next (conditioned, say, on still being there in the next moment). For example, in order to claim that counting frequencies should give you those probabilities amounts to accepting something along the lines of Elga’s Principle of Indifference37A. Elga, Defeating Dr. Evil with self-locating belief, Philos. Phenomenol. Res. 69(2), 383–396 (2004); download from author’s homepage, which represents a logically independent addition to our physical theories38In C. L. Jones and M. P. Müller, On the significance of Wigner’s Friend in contexts beyond quantum foundations, Quantum 10, 2147 (2026), we argue that this principle is not as well-motivated as it might first seem, and that there are other plausible choices too, including ones that would lead to very different conclusions from counting.. Clearly, it would be beneficial for cosmologists to be able to use this reasoning to rule out Boltzmann-brain-dominated models, but Restriction A for N = 1 observer applies: physics does not tell you whether you should believe that you are a Boltzmann brain.
A second class of puzzles where Restriction A applies are situations that resemble Parfit’s teletransportation paradox39D. Parfit, Reasons and persons, Oxford University Press, Oxford (1984).: these are scenarios where a given observer is undergoing some sort of duplication procedure (think of the Star Trek episode “The Enemy Within”). For example, suppose that you will be scanned in all detail (while destroying the original, as in Section 1), and a large number N of copies will be created which will all make different observations in the future. What should you believe about your future experiences in this case? At first sight, it seems like assigning equal probability to every copy is natural, but what would you do if, in fact, an infinite number of copies were created, and with increasing n, the nth copy will more and more deviate from the original, but only ever so slightly from copy n to n + 1? What if the copies are created also at different times? We have no idea what to say in this case, and our physical theories have nothing to say about what you should believe to experience next in this scenario40I do not believe that it is relevant to acknowledge that we will not practically run into a scenario of this form any time soon: our way to respond to those puzzles should in principle apply to all logically conceivable situations; if it does not, this is a sign of incomplete understanding. Furthermore, Everettians in particular might want to acknowledge that this scenario is perhaps not that extraordinary after all.. This is an instance of Restriction A for N = 1 observers. In41C. L. Jones and M. P. Müller, On the significance of Wigner’s Friend in contexts beyond quantum foundations, Quantum 10, 2147 (2026)., we construct a more elaborate version of a multiplication thought experiment that demonstrates an instance of Restriction A for N = 2 observers, robust to future changes of our physical theories, which resembles a probabilistic version of the Frauchiger-Renner paradox42D. Frauchiger and R. Renner, Quantum theory cannot consistently describe the use of itself, Nat. Commun. 9, 3711 (2018)..

Algorithmic idealism, as described below, can be understood as a reaction to Restriction A in the following sense. In this conceptual framework, Restriction A for any given single agent (N = 1) is seen as a serious problem that needs to be alleviated, because it reveals the inability to predict something about the results of actual experiments that somebody can do. For example, you can in principle (and, in the perhaps not so far future, in practice) agree on being copied into a computer simulation in some sense, and see what happens to you. Despite the fact that the outcome cannot be intersubjectively shared (as explained above, this is a prerequisite for Restriction A to even apply in the first place), it seems absurd to believe that there was nothing that could be said (probabilistically, say, or plausibilistically43T. Fritz and M. Leifer, Plausibility measures on test spaces, arXiv:1505.01151., or in some other sort of mathematical formulation) about which sort of outcome of this experiment you ought to expect to experience. After all, the world will kick back at you and generate some subjective outcome, and something must determine the nature of this outcome. Even claiming that nothing can be said in this case is just an utterance of a human being in need of clarification, which means in need of mathematical formalization. Indeed, algorithmic idealism suggests a particular resolution of Restriction A for N = 1 agents via Postulate 2 below (and via its formalization in some specifically chosen mathematical model).
However, algorithmic idealism does not claim to resolve Restriction A for N ≥ 2 agents, but rather suggests to accept it: according to its predictions, different agents do not in general share a common world into which they seem to be embedded. Instead, “objective reality” is an approximate and emergent statistical phenomenon that does not apply in all cases (see Subsection 6.3 below). Indeed, Restriction A for N ≥ 2 observers (and the recent results in Ref.44K.-W. Bong, A. Utreras-Alarcón, F. Gharafi, Y.-C. Liang, N. Tischler, E. G. Cavalcanti, G. J. Pryde, and H. M. Wiseman, A strong no-go theorem on the Wigner’s friend paradox, Nat. Phys. 16, 1199–1205 (2020). showing that, under some natural assumptions, all future physical theories will suffer from it) is taken as corroborating evidence for the correctness of algorithmic idealism’s strategy to drop the assumption that agents are fundamentally embedded into external worlds.
Q8: I am a realist, and I don’t care about the this sort of nonsense theory.
A: Everybody is free to ignore my approach, but I would invite you to recall why you are a realist in the first place: probably it is your value not to fool yourself and to hold on to the scientific method; probably you want to say that the things science talks about are actually real in some strong sense of the word; and maybe you take a passionate stance against pseudoscience, mysticism and other nonsense. Algorithmic idealism is on board with all of this. It does not claim that the world is “not real”; it simply claims that it is not fundamental. It is a mathematically fully rigorous approach, and one that admits several possibilities of falsification. The goal is not to answer philosophical questions such as “what is the world really made of?”, but to make concrete predictions, albeit for unusual scenarios (see above).
Q9: Aren’t you making unnecessarily speculative claims by dropping most of our intuitive metaphysical assumptions?
A: Being speculative and being counterintuitive are two very different things. It is true that many philosophers regard it as a weakness of a theory if it is counterintuitive, and if it implies “extravagant metaphysics”. I think this is a mistake: all essential progress in physics that we have made in the past has demolished some of our previous intuitive metaphysical assumptions.
Q10: If “having an intuitive metaphysics” is not one of your values, then what are your values?
A: These include mathematical rigor, conceptual clarity, simplicity, and empirical adequacy. Certainly, for a theory to be interesting, it should also do something for us, e.g. make concrete predictions for some scenarios that we are interested in. Beyond that, I do not think that it matters whether the theory happens to be in line with human intuition. Our intuition has evolved to help us survive and reproduce, but not to understand reality beyond its correlation with these goals.
Q11: Algorithmic idealism predicts that the external world is a computer program. But our world is continuous, not discrete! Aren’t you following a naive “digital physics” paradigm?
A: Algorithmic idealism does not claim that the world is discrete in any naive sense. It only models the state of the observer as discrete (think of the data in your observations and memory), but even this is not a necessary feature and can be changed by changing the model. Regarding the external world, the relevant feature is not cellular-automaton-type naive discreteness of spacetime, but a physical version of the Church-Turing thesis: given a description of some experiment, there is an algorithm that computes the probabilities of the possible outcomes. Note that this is compatible with different notions of continuity; for example, many continuous mathematical structures (including those described by differential equations) admit finite mathematical definitions. A.id. predicts that the external world is essentially a computational process, but it does not claim that it resembles — intrinsically for its “inhabitants” — in any way the computational models that we humans have introduced, such as Turing machines or cellular automata.
Q12: But the world is quantum, not classically probabilistic! However, all I see in your formalism are statistical probabilistic statements, not quantum states.
A: The empirical predictions of quantum theory are all about probabilities of outcomes of measurements (or recordings or experiences), and this exhausts everything that we have ever seen in any experiment. These Born rule probabilities behave in unexpected, “nonclassical” ways, e.g. they violate Bell inequalities in a particular causal structure (the Bell scenario) where bare classical probability theory predicts no such violations. But they are still probabilities. In particular, as shown in my 2020 paper, a quantum computation is a valid “computational ontological model” according to my definitions, and hence a possible external world into which an agent may find itself embedded. An external quantum world is perfectly compatible with algorithmic idealism.
Q13: Still, you could have built in the formalism of quantum theory right from the start! Why have you not done it?
A: Because my hope is that some nonclassical aspects of quantum theory can be shown to be predictions of algorithmic idealism. (Or conversely, if it turns out that completely classical phenomenology is typically predicted for agents, then this is an opportunity for falsification of a.id.). In my 2020 paper, I have indeed given a preliminary result (a valid theorem, but “preliminary” because it still rests on too many assumptions) which shows that the violation of Bell inequalities, but preservation of the no-signalling principle can sometimes be expected to result from a.id. Intuitively, this is because “resetting an agent’s self state resets its external world”, leading to statistical consequences (akin to “cosmological detection loopholes” etc.) that are counterintuitive and indeed impossible in a classical and standard ontology.
Q14: What is algorithmic idealism’s relation to QBism and to the many-worlds interpretation?
A: I have the highest respect for people who work on both of these interpretations and their variants (including other neo-Copenhagen interpretations), and am deeply interested in both. If I were a realist, I would subscribe to the many-worlds interpretation. However, the whole point of algorithmic idealism is not to be a realist in the traditional sense, because traditional realism is an in-principle obstacle for even attempting to come up with a rigorous theory that addresses the questions that algorithmic idealism targets (recall Section 1). But I believe that no experiment we will ever do will be in contradiction with many worlds, and I am technically strongly interested in it, because its burden to derive the Born rule for branching observers has some overlap with a.id.’s task to define transition probabilities between self states.
As for QBism, I have a deep affection for its views, and certainly agree with its tenet that a quantum state should best be viewed as a “catalog of probabilities”, and that these are probabilities of an agent’s future experiences. However, I believe that there is both room for and necessity of a notion of probabilities that is closer to our idea of “objective chances” rather than “personal beliefs”. (To clarify: I believe that both notions can peacefully coexist within the same formalism.)
Q15: So, then, what is your interpretation of quantum theory?
A: You see some answers in the main text. I find Berghofer’s modification of QBism appealing, useful, and largely in line with how I think about the quantum state. In particular, I think that physics deals with probabilities that do not say what you believe, but what you should believe.
But more importantly, I am simply not interested in interpreting quantum theory if we understand the word “interpretation” in a traditional sense: as telling a convenient story about “what is really going on in the world”. I do not believe that the notions of “world” and “really going on” have any foundational significance. I am however very much interested in the interpretation project if it is understood more broadly: as understanding what quantum theory teaches us about the nature of reality. Proposing algorithmic idealism is (among other things) a contribution to this project.
Q16: So you’re proposing a “theory of everything”? That’s preposterous — and it puts your work high up on my crackpot index!
A: This is not a theory of everything! It has nothing to say about almost all questions that most physicists are interested in. For example, it will tell you nothing about quantum gravity or particle physics. It is true that its main hypothesis makes a highly unusual foundational claim, offering an explanation for why we see simple laws of physics in the first place. However, it only predicts the algorithmic simplicity and probabilistic nature of these laws, not their specific form. Indeed, by claiming that these are contingent, algorithmic idealism predicts the unavoidability of its own limitations.
Q17: Why is this only work in progress? What is the “erasure problem“?
A: Algorithmic idealism is a general approach that admits several different concrete mathematical formulations, i.e. models. Because of the way that algorithmic information theory (which is used in a.id.) has previously been formalized, a.id.’s simplest formulation — the “bit model” — assumes that self states always grow one bit at a time. That is, fundamental “erasure” of information in the self state is not possible in this model, and this assumption is not well-founded (and arguably only true approximately in some idealized situations). The erasure problem is to construct an alternative model of a.id. which does not make this assumption, i.e. which admits fundamental erasure of self state information, but which still admits versions of the mathematical theorems (including the emergence of a simple probabilistic external world) that have been proven for the bit model. This is what I am working on at the moment.
4. Algorithmic Idealism in a Nutshell
How do we respond to Restriction A? In the case of N ≥ 2 agents, the nonexistence of a joint probability distribution for the observations of all agents can be interpreted45It certainly does not have to be interpreted in this way (e.g., one might drop some background assumptions such as locality that underlie the corresponding no-go theorems), but it is a well-motivated and natural possibility. as evidence that we should not always regard observations or events as absolute (see e.g.46F. A. Fuchs, Notwithstanding Bohr, the Reasons for QBism, Mind and Matter 15(2), 245-300 (2017).; J. B. DeBrota, C. A. Fuchs, and R. Schack, Respecting One’s Fellow: QBism’s Analysis of Wigner’s Friend, Found. Phys. 50, 1859–1874 (2020).; H. Zwirn, Are Events Absolute?, arXiv:2507.14672.), and algorithmic idealism as described below will agree with this. The case of Restriction A for a single agent, N = 1, is however even more troublesome: it means that an agent can perform an experiment where they will learn some outcome, but there is nothing that can be said about what they should expect to observe. As explained further above, I regard this as absurd, and interpret it as a shortcoming of our given theories. If one takes this viewpoint, how does one react to it?
One option is certainly to double down on physicalism, and to insist on saying that “what should I expect to experience next?” is not usually a well-defined question. In this view, we should see this as a kind of pragmatic question that sometimes does not have an answer, and that will often have a vague answer, similarly as the question “Are viruses alive?”
However, here I suggest to explore a second option, which is to assume that (a specific version of) this first-person question does always have an objective answer, and to work out a theory that aims at supplying this answer at least in principle. The motivation to do so is two-fold: pragmatically, we will at some point be in desperate need of guidance in exotic situations such as the one of Section 1, and a precise theory that offers such guidance and that is also in agreement with the standard physics predictions in mundane situations seems to be a good tool to aim for. Furthermore, as I have argued in Section 2, quantum theory suggests that the question of “what should I expect to observe next?” is a more fundamental, natural and fruitful question to ask than “what is the case in the world”. We may see this as a hint from modern physics that we can hope to get closer to the truth by attempting to answer the former rather than the latter, and we can hope that trying to do so may indirectly tell us something interesting about the world, too.
The goal of algorithmic idealism is to implement this second option. Despite its name, I am aiming for a formal, mathematically rigorous approach for which higher-level concepts such as consciousness or belief do not play any fundamental role.
A first step is to put aside the concept of “belief” and instead to focus on the current state of the observer (for any given single, subjective moment), in an abstract, information-theoretical sense. For a human observer, for example, this could be the pattern47D. C. Dennett, Real Patterns, J. Philos. 88(1), 27 (1991); link on PhilPapers. of neuronal connections in their brain (this description is only meant to be helpful for our intuition and not to become an actual part of the theory). This corresponds roughly to what Parfit called a “person stage”48D. Parfit, Reasons and persons, Oxford University Press, Oxford (1984).. Among other things, this implies that “agents” or “observers” will not be primitive notions of algorithmic idealism, but only momentary “snapshots” of the pattern, structure or information content that defines an agent or observer at some given moment. These will be called “self states”49In the earlier publication M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)., these have been called “observer states”., see Figure 2 for an illustration and further comments.
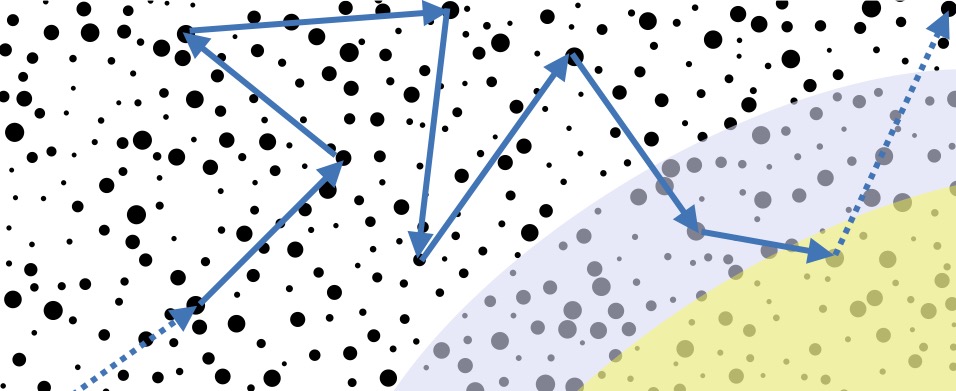
Figure 2. The set of self states \( \mathcal{S} \), which will typically be modelled as a countably-infinite set, illustrated as a set of black dots. Self states are simply abstract patterns (perhaps formalized as finite binary strings or natural numbers), and only a small subset of those (indicated in light blue) will have an interpretation as describing a (momentary snapshot of an) agent. Among those, a very small subset (highlighted in yellow) will have an interpretation as describing conscious self states. Neither agenthood nor consciousness, but only the abstract mathematical description is relevant for algorithmic idealism, and it will in particular contain a structure that says which self states \( y \) are more or less likely, given a current self state \( x \). If this is mathematically described by a conditional probability distribution, then we obtain a Markov process; however, even in the simplest model of algorithmic idealism (the bit model), this likelihood is described by an infinite collection of algorithmic priors. Some self states will be more likely to obtain on average than others, which is indicated by the different dot sizes. What is not shown is the abstract computability structure which will in the end determine the likelihood of transitions, corresponding to what a universal method of induction would predict50Thanks to www.freepik.com for the black dot picture..
A second step is to let go of all human-centric aspects and to pursue a completely abstract approach: a self state can be any sort of pattern, in some mathematically, abstractly defined set of all possible patterns. Only a tiny subset of those patterns would deserve to be interpreted as describing something like the momentary state of an “observer” (let alone a human or conscious observer). At the level of fundamentality that we are targeting, it would be completely off the mark to introduce a specific model of an observer, or to make any specific assumptions about its composition or function. The most modest and thorough approach is a maximally abstract one, in which all aspects of how we think of observers or agents are tentatively treated as contingent.
This leads us to a formulation of the first postulate of algorithmic idealism:
Postulate 1 (Self States). There is a set \( \mathcal{S} \) of “self states”, the collection of patterns that one can be at any given subjective moment. Everything that is to be said about a given agent at some moment, including all inferences to be drawn about its past or future, is determined by its self state.
In particular, and perhaps most counterintuitively, algorithmic idealism denies that agents are fundamentally embedded into some external world: an agent at some given moment is completely characterized by its self state (which is a standalone pattern), and not by its spatiotemporal location inside some external world. In cases such as the Boltzmann brain problem, for example, where there are many locally indistinguishable copies of an agent, it rejects the usual “self-locating uncertainty” intuition that the agent is actually one of the copies, but does not know which one. Instead, according to algorithmic idealism, the agent (at that given subjective moment) is its self state, and this abstract pattern just happens to be represented, or realized, in each one of the copies. In some sense, the agent should think of itself as the equivalence class of all these realizations (ordinary brains and Boltzmann brains and all other, potentially completely different, realizations).
At first sight, this seems absurd: after all, will the agent not make another observation soon that will either confirm or disprove its concerns of being a Boltzmann brain, and hence retrospectively say that it was actually the copy on the planet, and not the random fluctuation out there? On second thought, however, the apparent contradiction gets resolved by two insights. First, algorithmic idealism is constructed to avoid the “standard methodology” described in Section 3, and to allow agents to predict what they will see next without grounding this on the expected state of the world into which they are embedded. Hence, by construction, what they should believe cannot depend on whether they are “actually” surrounded by a planet-like environment or high-entropy radiation. Second, as will be explained in Section 6, algorithmic idealism predicts that agents can often think of themselves as “effectively embedded”: what happens to them will often look to them to excellent approximation as if they were a part of some external world with algorithmically simple, probabilistic laws of nature. In the cosmology example, this results in the consequence that the agent will probably experience “planetary business as usual” next, regardless of the number of Boltzmann brains, even though the question of whether it actually is a Boltzmann brain or not is ill-defined. This will be discussed in more detail in Section 6 below.
Dropping the standard methodology, we now need a postulate that implies what an agent51I have remarked above that the notion of “agent” is not a primitive of algorithmic idealism, but only the notion of a “momentary snapshot” in terms of a self state. However, it will still be linguistically convenient to use the words “observer” or “agent” in the colloquial descriptions, simply because it would otherwise be difficult to convey the right intuitions for us human beings who are used to think in terms of things that persist over time. should believe to experience next, and since we are not grounding this on an external world in the usual sense, the answer can only depend on the agent’s momentary self state. Since we have decided to do without vague terms such as “belief” or “experience” in algorithmic idealism, this question has to be replaced by another one: If an agent is in self state \( x \) now, in which self state \( y \) will it probably be next? By construction, we cannot rely on our usual laws of physics to ground this question. Instead, a fundamental idea of algorithmic idealism is to rely on a weaker assumption that underlies our trust in empirical science in the first place: that induction is possible. More specifically, I implement this idea in the form of the following postulate:
Postulate 2 (State Change). If you are in self state \( x \) now, you will be in another self state \( y \) next, and which one this will be manifests itself as a random experiment for you. The likelihood of some \( y \) next, given \( x \) now, has an objective value, which expresses what you should believe will happen to you next, if you knew your current self state. The mathematical structure that defines its value formalizes a universal method \( M \) of induction.
Induction, broadly speaking, is a method to predict future observations by extrapolating regularities of past observations. What I mean by “universal” is a method that does not only work under the assumptions that we navigate within our own universe, but in a large class of conceivable environments. The possibility of inductive inference is one of the main assumptions of the scientific method. Here, we stipulate that induction should in principle always be possible, even in exotic situations, but in the following indirect way: there is a method of induction \( M \) such that the likelihood of becoming \( y \) next, given that one is \( x \) now, is exactly the one that is predicted by \( M \). In other words, a hypothetical third person that uses method \( M \) could correctly (albeit not deterministically) predict any other agent’s future self state, if it were given a complete description of that agent’s current self state. A consequence of Postulate 2 is that regularities that are present in your current self state will tend to persist in your private future, because methods of induction assign high probability to this being true.
Probabilities obtained by some method of induction are naturally interpreted in a Bayesian way: many such methods begin with a certain choice of prior, and apply Bayesian updating upon obtaining new information (this is in particular true of Solomonoff Induction, used in the bit model below). However, here, the mathematical formulation of a method of induction is detached from its epistemic origins: rather than describing someone’s beliefs about an unknown future, the values that it defines mathematically are now interpreted as some sort of objective chance of turning from some given self state to another one. In more detail, they are supposed to be interpreted in a similar way as Berghofer’s DEJI interprets quantum probabilities: not as expressions of what somebody believes, but what they should believe if they were told the current self state52This does not imply that the agent itself (which is in self state \( x \) now) can use method \( M \) to predict its own future experiences directly. After all, the agent will not in general have complete knowledge of \( x \), and some self states will represent observers that are incapable of reasoning, or that are simply patterns which defy any interpretation as “observer” or “agent”. However, agents like us who are able to reason rationally may still use the resulting model of algorithmic idealism to predict something about their future observations. This can be done either by working out general predictions of algorithmic idealism that are independent of the specific form of the current self state \( x \), or by analyzing the consequences of some (incomplete, but non-zero) knowledge of \( x \)..
Postulates 1 and 2 are intentionally formulated in such a way that they admit of several possible rigorous mathematical formulations, or models. For every choice of self states \( \mathcal{S} \) and method of induction \( M \), one obtains a different model. One simple, preliminary model, the bit model, has been introduced in Ref.53M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020).. It will be described in Section 5 below. Different mathematical models (and the associated methods of induction) may rely on different mathematical definitions of likelihood, e.g. on a single conditional probability distribution, on a collection of several such distributions (which is the case for the bit model below), on a notion of imprecise probability54P. Walley, Statistical Reasoning with Imprecise Probabilities, Monographs on Statistics and Applied Probability, Springer Science and Business Media, 1991., or on plausibility measures55T. Fritz and M. Leifer, Plausibility measures on test spaces, arXiv:1505.01151; N. Friedman and J. Y. Halpern, Plausibility Measures: A User’s Guide, in P. Besnard and S. Hanks (eds.), Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence (UAI1995), Morgan Kauffman, 1995.. The precise conceptual interpretation of these “values” of likelihood, as currently sketched in Postulate 2, may have to be adapted on a case-by-case basis. Algorithmic idealism should therefore be seen as a kind of conceptual framework rather than a single theory, because it admits many different mathematical realizations.
As an analogy, consider the general idea that physical space could be curved rather than flat, or more generally, non-Euclidean in some way. This single idea has many possible mathematical realizations that make very different physical predictions, even though some predictions may be universal (such as a violation of the triangle postulate). The question of which one of the resulting theories is correct (if any) is ultimately a matter of empirical observation and experiment. In fact, the idea that non-Euclidean geometry applies to our world predates the theory of relativity. In 1872, the German astrophysicist Karl Friedrich Zöllner56H. Kragh, The first curved-space universe, Astronomy & Geophysics 53(5), 5.13–5.15 (2012). suggested that we may live in a non-Euclidean curved universe. This allowed him to suggest a solution to what is known as Olbers’ paradox: if the universe had positive curvature, it could have finite volume without having a boundary, which would allow us to understand why the night sky is dark. Ultimately, further experimental results, such as the perihelion precession of Mercury’s orbit or the outcome of the Michelson-Morley experiment, were necessary to arrive at yet another modification of the conceptual framework which ultimately resulted in General Relativity: that we should consider curved spacetime rather than space. Nevertheless, it would be fair to say that Zöllner’s idea turned out to be essentially correct: finiteness of a non-Euclidean universe resolves Olbers’ paradox.
In hindsight, while Zöllner should not have hoped to guess the correct theory of the universe a priori, he would have been correct to anticipate the general field of mathematics that would be involved in its formulation: differential geometry, because this is the arena of reasoning that allows us to describe spatial geometries which are locally familiar but potentially globally unusual. We can similarly guess what field of mathematics will be relevant for all formalizations of algorithmic idealism. In the standard picture of an agent or observer, we would say that the observer’s state contains a large amount of memory and experiences of an external world; that is, variables which are correlated with the variables that comprise relevant aspects of the outside universe. This is the paradigmatic scenario described by (standard) information theory57T. M. Cover and J. A. Thomas, Elements of Information Theory, John Wiley & Sons, 2006.: essentially, an observer’s state would correspond to information, and it would be information about an external world. However, algorithmic idealism concerns the structure of the observer (at some given moment) and its regularities (because a method of induction must be applicable) without reference to anything external. We need an area of mathematics that is concerned with the structural regularities in a bare, concrete collection of standalone data, not in a random variable that is potentially correlated with another variable. Such a field exists: algorithmic information theory (AIT)58M. Hutter, Universal Artificial Intelligence – Sequential Decisions Based on Algorithmic Probability, Springer, Berlin, Heidelberg, 2005.; M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008., and hence the name of the approach.
Q18: Can algorithmic idealism be tested?
A: In some specific sense yes, but there is a lot to be said here. What most people will have in mind is a sort of “gold standard” of testing: a theory makes a new and unexpected prediction, experiments are built that test the prediction, and the prediction is confirmed. But complying with this gold standard has become increasingly difficult in fundamental physics, and perhaps impossible, over the last couple of decades. For example, nothing like this has ever been possible for any candidate theory of quantum gravity. Indeed, it is even notoriously difficult to show that a given theory of quantum gravity reduces to general relativity on large scales, which would be an excellent first test.
Similarly, a first test of a.id. is whether it reproduces our standard view of physics to good approximation: for example, the view that we find ourselves in an external world that evolves according to some simple, probabilistic laws; or the general fact that these probabilities seem to be behave nonclassically (and ultimately quantumly). The former is already a proven theorem, and the latter is work in progress (with some preliminary results). There are many other ways in which a.id. could fail to reproduce things that we see; for example, it could predict large fluctuations of the “laws of nature” which we do not observe, and be ruled out on that ground.
A second way to test a.id. is by checking whether it admits a consistent treatment of the kinds of conceptual puzzles that it targets, such as the Boltzmann brain problem. It might fail to do so and lead to similar kinds of “cognitive instability” as pointed out by Carroll; but, as explained in the main text, things look good on this front (but further testing is required).
A third way of testing follows from recalling what types of predictions a.id. actually targets: experiments that can be privately, but not intersubjectively performed and analyzed. Hence, one can in principle test a.id. by private experiments. This may involve science fiction scenarios such as the simulation problem of Section 1. But it also includes another experiment that we will all perform one day, and very privately so: death. Some models of a.id. predict that we should not think of death as transitioning into a kind of “eternal unconscious state”, but rather as “falling out of the universe” in some sense. Due to the “no-erasure problem”, a.id. does not currently make any concrete claims about this. But if a model is developed that does, then it can in principle be tested privately in this way (though you might forget on the way what you are actually testing).
Q19: Your agents or observers are very passive: they move from one self state randomly to another, without ever making any choices or performing any actions. In particular, they do not have free will. This seems abhorrent and fundamentally wrong.
A: First, note that this potential point of criticism is not specific to algorithmic idealism, but would apply as it stands to all our established physical theories: neither classical mechanics nor general relativity, quantum mechanics, quantum field theory, thermodynamics, or any other physical theory has a notion of “free will” built into its fundamental equations or postulates. And this is for a good reason: “free will” seems to be a high-level notion such as “beauty” or “consciousness” that would not sit easily in any formal mathematical framework that aims for simplicity.
Second, compatibilists such as Daniel Dennett have (as I believe) convincingly argued that free will is fully compatible with determinism. I do not agree with everything that Daniel Dennett said (for example, I am not an illusionist about consciousness), but I believe that this point was essentially correct: rather than asking “whether one could have acted differently”, for example, one should rather ask whether one is the source of one’s decisions and actions. In a nutshell, I strongly believe that we have free will, and that this is not in contradiction to the fact that physical laws do not explicitly include a notion of free choice. In any case, the debate about this is no different in the context of algorithmic idealism than it is in the context of any other physical theory.
Q20: But I am an operationalist, and I believe that some notion of free choice is extremely important for our understanding of quantum theory — if only to admit talking about the violation of Bell inequalities.
A: The notion of “free choice” of the measurement settings in a Bell scenario is a causal-statistical notion, not a metaphysical one: it simply means that the variables \( x \), \( y \) denoting the choices of the spacelike separated experimenters are uncorrelated with all relevant variables that are not in their respective future lightcones. This formulation in itself is independent of the metaphysical question of free will. It is true that we would like to have some notion of intervention in order to talk about such experiments in the context of a given theory (such as quantum theory, classical mechanics or a.id.), but this can be an effective notion: for example, in classical mechanics, it could amount to the notion that we can in some sense control the initial conditions of a mechanical experiment; in quantum theory, we might want to use half of an entangled state (a mixed state) to control the setting; in my 2020 paper, I give an example that does something analogous in algorithmic idealism, and use it to argue that the violation of Bell inequalities despite no-signalling is under some assumptions a generic prediction of a.id. — acknowledging explicitly the importance of settings such as the Bell scenario. In summary, you can be an operationalist without relying on any metaphysical notion of free will, and without any fundamental implementation of “free choice” in the very basic postulates of your theory.
Q21: In a.id.’s bit model, the universal prior determines the probabilities of an agent’s future observations, hence we should expect to have a “simple” self state of small Kolmogorov complexity. However, from experience, it seems that we make extremely complex observations (even technically, when we observe a long sequences of coin tosses, for example). Isn’t this an obvious contradiction?
A: This is a very common misunderstanding: we should not expect that our self state \( x \) has small Kolmogorov complexity. As is most clearly expressed in the “Inverse Solomonoff Induction” theorem in the main text, in the long run, we may expect that our self state \( x \) is a typical outcome of a “simple” stochastic process \( \mu \). “Simplicity” means that \( \mu \) has a short program on a universal monotone Turing machine, and those machines can obtain random bits for free (for example, a process resembling a sequence of identically distributed, independent coin tosses is simple in this sense). As the coin toss example shows, typical outcome sequences of such simple processes will generally have high Kolmogorov complexity. In summary, a.id. predicts that we find ourselves embedded in a simple probabilistic process (“external world”), but that the concrete outcomes of this simple stochastic process which we observe are typically very complex. This is broadly in line with our physical observations.
5. Algorithmic Information Theory and the Bit Model
AIT is concerned with the information content of individual chunks of data, usually described in terms of the finite binary strings, \( \{0,1\}^*=\{\varepsilon,0,1,00,01,10,11,000,001,\ldots\} \), where \( \varepsilon \) is the empty string, or the integers, \( \mathbb{N}_0=\{0,1,2,3,4,5,\ldots\} \). The most well-known quantity studied in AIT is Kolmogorov complexity: if \( x \) is a binary string or an integer, then \( K(x) \) denotes the length of the shortest program for a universal Turing machine U that produces \( x \) as its output. In the following, let us focus on the binary strings for convenience. Suppose that we generate a string \( x \) of length \( n \) by tossing a fair coin \( n \) times. Then, with high probability, \( K(x)\approx n \), because the shortest computer program to generate \( x \) will typically be “print \( x \)”, i.e. a program that lists all the bits of \( x \). On the other hand, if \( x \) is a string of \( n \) zeros, \( x=\underbrace{000\ldots 0}_n \), then \( K(x)\approx\log n \), because we only have to tell the Turing machine how many times it has to print a zero, which can be done by specifying the approximately \( \log n \) (in base 2) binary digits of \( n \). Similar reasoning applies to the first \( n \) binary digits of \( \pi \), or of \( \exp(\sqrt{2}) \), for instance.
The exact definition of Kolmogorov complexity depends on some choices of the Turing machine model that is used in its construction. For example, Kolmogorov complexity \( K \) defined above is usually defined for so-called prefix-free Turing machines (for which every program needs to describe where it ends), but there is another version called \( C \) for “bare” machines without this requirement. The fact that there are many possible definitions of its basic quantities implies many different possibilities to potentially ground a formalization of algorithmic idealism on AIT.
AIT also allows us to ask, for example, how likely it is that the Turing machine \( U \) generates some given output \( x \), if it is supplied with random input. How this is defined exactly depends on choices about the details of the working of the Turing machine. For prefix-free Turing machines, the textbooks give the definition of algorithmic probability $$m(x):=\sum_{p:U(p)=x} 2^{-\ell(p)},$$ where \( \ell(p) \) denotes the length of the binary string (program) \( p \). This is interpreted as the probability that \( U \) outputs \( x \) on some input that is chosen by a sequence of fair coin tosses. It turns out that $$-\log m(x)=K(x)+\mathcal{O}(1).\tag{1}\label{eq1}$$ This notation means that the difference between \( \log m(x) \) and \( K(x) \) is bounded in absolute value by a global constant that is independent of \( x \). This example already demonstrates some features of the scientific practice of AIT: researchers in this field are typically not interested in the actual values of quantities like \( K(x) \) or \( m(x) \) (in fact, these numbers are typically not computable), but in the scaling of these quantities with respect to other quantities such as the length of \( x \), or the comparison of such quantities59In some sense, this resembles scientific practice in physics, where we sometimes say things like “Suppose that the interaction energy \( \Delta \) is small compared to the total energy \( E \)” etc.. This attitude also eliminates most of the worries arising from the freedom of choice of universal Turing machine \( U \): for any other universal machine \( V \), we would have \( K_U(x)=K_V(x)+\mathcal{O}(1) \), where \( K_U \) denotes Kolmogorov complexity as measured with respect to the machine \( U \). That this sort of curious interplay between exact definition and (sort of) vague comparison-type application leads to a meaningful field of inquiry (and, in fact, to immense mathematical beauty) is a fact that cannot be conveyed in terms of the theory itself, but only be experienced when actually working with AIT.
Equation \( \eqref{eq1} \) says that strings \( x \) which are simpler (in the sense of having a shorter description on a universal Turing machine) are more likely (with respect to the distribution \( m \)). This is a general phenomenon for probabilistic quantities introduced and studied in AIT: they favor simplicity, resembling the intuition of Occam’s razor. Crucially, AIT allows us to define conditional versions of \( K \) and \( m \) that are potentially relevant for formulations of algorithmic idealism. For example, expressions60The definitions of these quantities are not relevant for the present discussion, and they can be found in M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008.. such as \( K(y|x) \) or \( C(y|x) \) quantify how much additional information a machine needs to produce \( y \) if it is given \( x \) for free; and conditional probability distributions such as \( m(y|x) \) or \( M(y|x) \) tell us how likely it is that a machine will output \( y \) if it is given \( x \) for free, resp. how likely it is that the machine will output \( y \) after it has output \( x \).
Intuitively, conditional probabilities such as \( M(y|x) \) will be large if and only if it is easy to generate \( y \) from \( x \) on a Turing machine, e.g. if \( y \) contains many of the computable regularities of \( x \). If so, then this suggests the idea that an expression like \( M(y|x) \) might be used as the basis of a method of inductive inference, and then perhaps the result could play the role of the method of induction mentioned in algorithmic idealism’s Postulate 2 above. There is at least one version of conditional probability for which this intuition can be made rigorous, resulting in a method of inductive inference that is known as Solomonoff induction61M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008.:
Solomonoff induction. Suppose that you observe one bit after the other, and you have seen the \( n \) bits \( x_1^n = x_1 x_2 \ldots x_n \) so far. Then, predict that the next bit will be \( b \) with probability \( \mathbf{M}(b|x_1^n) \), which is the probability that the universal monotone Turing machine (defined in Ref.62M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008.) will output \( b \) after having output \( x_1^n \).
That this is a good method of prediction can be shown as follows63M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008.. Suppose that the bits that you see are actually generated by some computable process \( \mu \) (a “recursive measure” in the terminology of Ref.64M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008.), which you do not know. Then, with \( \mu \)-probability one, $$\lim_{n\to\infty} |\mathbf{M}(b|x_1^n)-\mu(b|x_1^n)|=0\quad (b\in\{0,1\}).\tag{2}\label{eq2}$$ That is, in the long run, algorithmic probability \( \mathbf{M} \) will almost surely agree with the actual probabilities \( \mu \) determined by the unknown computable process that generates the bits that you see. For example, suppose that the process always outputs deterministically the bit 1, i.e. \( \mu(1^n)=1 \) for all \( n\in\mathbb{N} \), where \( 1^n=\underbrace{111\ldots 1}_n \). Then \( \mathbf{M}(0|1^n)=2^{-K(n)+\mathcal{O}(1)} \), which tends to zero and is of the order \( 1/n \) for most \( n \). In this sense, after seeing \( n \) ones, Solomonoff induction predicts that you will probably not see a zero next, as expected from a method of induction.
Based on this result, I have constructed a preliminary formalization of algorithmic idealism in Ref.65M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)., the bit model. Its set of self states is the set of finite binary strings, \( \mathcal{S}=\{0,1\}^* \). The method of induction is Solomonoff induction. More concretely, the claim is that self state \( x \) is always followed either by self state \( x0 \) or by self state \( x1 \) (that is, \( y \) is obtained by appending a single bit \( b \) to \( x \)) and the probability66In more detail, this defines a subnormalized measure, i.e. the sum over \( b \) of \( \mathbf{M}_U(b|x) \) is in general less than one. The actual transition probabilities will be given by the Solomonoff normalization of this semimeasure, as defined in M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008, which is a normalized probability measure. is given by \( \mathbf{M}_U(b|x) \). In more detail, the likelihood of changing self state to \( y=xb \) is characterized by the set of all \( \mathbf{M}_U(b|x) \), over all universal monotone Turing machines \( U \), and the predictions of the theory are by definition those that are invariant under the choice of \( U \). That is, the notion of “likelihood” is a more liberal one than a specification of a fixed probability distribution, and this is discussed in detail in Ref.67M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)..
This extremely simple model is quite powerful: it admits the rigorous proof of several significant predictions that I will describe in the following section. However, it has some undesirable features that motivate my current work on an improved version. In particular, it implies that a momentary state \( x \) has always complete information about what the previous self states have been (namely, the prefixes of \( x \)). This is both unrealistic (thinking, say, of human observers) and unmotivated. It is simply an artefact of the way that AIT has been pursued so far.
In the rest of the paper, I will focus on the conceptual aspects of the theory and set all technical details of AIT aside. In particular, instead of giving technical proofs of its main predictions in a particular realization such as the bit model, I will describe the main ideas for why these predictions should be expected to follow from Postulates 1 and 2 even beyond the bit model.
Q22: If there’s anything that determines my “self state”, then it is certainly my brain and nothing else. Isn’t your probabilistic law for self states denying this, and postulating an implausible mystical extramaterial influence?
A: Algorithmic idealism agrees with physics that it is empirically adequate to assume that the physical state of your brain determines your experiences, in the “standard regime” where you find yourself effectively embedded into some (this!) external world. From day one until the final day of your life (the “standard regime”), regardless of whether you are in everyday life, dreaming, meditating or taking substances, it is the physical functioning of your brain that exhaustively explains the content of your self state. To see how this can be true, and yet the postulates of algorithmic idealism can be true too, consider the fact that different causal explanations of facts often coexist peacefully. For example, here are two equally correct explanations for why there is a Great Wall in China: first, because some inhabitants of ancient China needed protection against various nomadic groups from the Eurasian Steppe, and decided to build it. Second, because of the initial state of the universe and the laws of physics, the atoms that make up the wall ended up attaining the positions that they are occupying now. Clearly, both explanations are correct (though perhaps not equally useful) and not in contradiction to each other, even though both offer apparently competing answers to the question of “how come” there is the Great Wall. Similarly, when you ask “what causes my self state”, then you can answer either “my brain”, or “the universal prior”, and both answers will peacefully coexist.
To elaborate further, according to a.id.’s bit model, it is fundamentally conditional algorithmic probability that determines your self state. However, as a consequence of that, it is often the case that in the long run, this self state evolution looks as if the self state were embedded into an external world \( W \) (including a brain) that can be regarded to cause (mechanistically, so to speak) this self state evolution — this is expressed by the “Inverse Solomonoff Induction” result in the main text.
In summary, algorithmic idealism doesn’t deny that your self state supervenes on your brain in some sense; it rather offers a possible deeper explanation for why this is so. Moreover, it suggests that this supervenience is only true under some conditions, and these are almost always satisfied in our lives, but not in all exotic situations, such as duplication, computer simulation, or death.
New questions will be added from time to time.
6. Predictions of Algorithmic Idealism
Every novel theory must reproduce the predictions of earlier theories to good approximation, in agreement with existing empirical results, and then it must do more. For algorithmic idealism to be successful, it should
- be consistent with the predictions of our physical theories in standard situations;
- explain facts that are simply assumed in our physical theories, e.g. why it typically appears to us that we are embedded into a probabilistic world with simple laws of nature; and
- give us concrete (and perhaps surprising) predictions for exotic scenarios such as the Boltzmann brain problem or the computer simulation of agents.
In this section, I will argue that algorithmic idealism can satisfy all these desiderata. I will do so via plausibility arguments, based on Postulates 1 and 2 of Section 4. In Ref.68M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)., I have given rigorous formulations and proofs of these claims for the bit model as described above. However, for the reasons mentioned above, the bit model has to be improved. My hope is that the colloquial argumentation of the present paper can be a useful guide for the proof of the claims in other mathematical formalizations of algorithmic idealism. It certainly gives a valid conceptual summary of what is going on in the technical proofs for the bit model of Ref.69M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)..
6.1. Consistency With Physical Predictions in Standard Scenarios
The main argument for why algorithmic idealism will be in agreement with our physical theories is that our physical theories seem to imply that formal methods of induction are in principle empirically adequate. Consider an agent characterized by some self state x which contains a lot of data. As we have said above, a self state need not correspond to anything that we typically interpret as an agent or observer, so let us consider planet Earth. Motivated by AIT, we may focus on versions of algorithmic idealism where the set of all possible self states is the finite binary strings, \( \mathcal{S}=\{\varepsilon,0,1,00,01,\ldots\} \). To relate Earth with a binary string, let us fix an arbitrary method for encoding an approximate description of a momentary70We may have to decide how to deal with relativity’s lack of absolute simultaneity and other ambiguities, but any decision for how to do so will considered to be part of the definition of the encoding procedure. Mathematically, the procedure must be computable, see the notion of a computational ontological model of the technical paper M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020). configuration of Earth into bits. For example, we might coarsegrain the shell of the sea level plus or minus one kilometer into approximate cubes of sidelength 10−9 meters, and store a couple of bits for each cube that describe the approximate material composition of the corresponding cube, resulting in an enormous chunk of data.
For the sake of the argument, imagine that we give this data to a team of brillant scientists that has access to astronomical computational power. We ask the team to make a prediction for what this source of data will yield next. (Even if we think of continuous time evolution in our world, the result of this discrete encoding procedure will discretely change in a non-zero but very small fraction of a second in the future, and this change is what the third party is supposed to predict.) Earth contains a lot of records about the universe in which it is located: there are fossils in the underground implying biological evolution, astronomical photographs in libraries that convey some knowledge about what the world looks like external to Earth, and movies or other subtle properties of its structure that reveal many aspects of the physical laws in the relevant regime. It is not unreasonable to expect that a complete description of the relevant laws of physics and, say, the relevant aspects of the state of the universe at the Big Bang can be extracted from this data in principle – after all, this is what we humans seem to accomplish successfully via science. Hence, the team of scientists should be able to accomplish their task successfully.
What this thought experiment then shows is the first step in the following three-step argument:
- We have heuristically argued, given the success of science, that good methods of induction – if they were supplied with a description of a momentary state of Earth as just described – should predict the same probabilities of future states of Earth as our best scientific theories. Hence if science makes correct predictions, good methods of induction will do so as well.
- As a next step, we lift this from a pragmatic, heuristic, methodological intuition to a precise mathematical claim: if we are given a mathematically well-defined method of universal induction \( M \) (such as Solomonoff induction defined above), then \( M \) should also make correct predictions about the probabilities of future states of Earth. This is much less intuitive, since the input to \( M \) is simply a bare self state; in the bit model, it is a long string of binary data. It may seem surprising (and for philosophically-minded readers highly dubious) that it is enough to have this data without any built-in semantics, such as a reference to spatiotemporal structure etc., and still to obtain correct predictions from it. But this is guaranteed by mathematical theorems (essentially \( \eqref{eq2} \) if the induced stochastic process on the self states is computable.
- Steps 1 and 2 have only been concerned with general properties of universal induction, formulated via well-known results of algorithmic information theory. Algorithmic idealism becomes only relevant now: it says that if you are Earth’s current self state71As discussed further above, self states are not in general associated to intuitive instances of “agents” or “observers”., then what you will become next is determined by \( M \) (in the bit model, this is algorithmic probability). In particular, it is not determined by the laws of any world in which you might imagine being embedded (actually, you are unembedded). Instead, \( M \) is the “law of nature”, and its action depends on the bare self state and not on anything external to it.
What steps 1 and 2 now show is that algorithmic idealism’s claim of what happens to you if you are Earth (in more detail, if you are its data defined by the specific choice of read-out procedure at a specific moment in time) is consistent with what happens to Earth according to our usual physical picture of the world (in the next moment).
In the above, there was nothing special about Earth or about the specific choice of encoding procedure. We could instead think of anything else that contains a large amount of data about our world, for example a human brain, a hard disc, or the left half of the brain of some mammal, to some level of detail of description. In all those cases, Postulate 2 should yield very similar (and asymptotically identical) claims for what happens to you if you are that thing72To be more precise, it is not about being “that thing”, but about currently being the self state that is encoded into it. as physics does.
In the bit model, we can be more specific what the requirements are for this consistency result to hold. Consider some bit-string-valued random variable x in the world (see the technical paper73M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020). for how this is consistent with quantum theory), changing over time in a way that its length does not decrease. For example, think of a video camera that is continuously filming Times Square and recording the pictures on a hard disc, where the video is encoded into bits. Or think of the “state of the Earth” example above, or a discretization (and arbitrary computable method of digitization) of your brain to some large accuracy over time, keeping all past information. Our physical theories tell us that the physical world generates a probability measure \( \mu \) on the possible histories of this bit string (for example, pictures of the Times Square showing all pedestrians suddenly floating up towards the sky has extremely small probability). If a suitable version of a physical Church-Turing thesis is true, then \( \mu \) will be a computable measure. (For this, not only the process defining the relevant aspects of the world, but also the definition of the random variable needs to be computable.) Then, Eq. \( \eqref{eq2} \) will be true: the probabilistic predictions of algorithmic idealism will in the long run agree with the probabilities obtained from actual physical evolution.
Recall that Postulate 2 is not a description of what we (or the agent) believe will happen next, but what they should believe. That is, it is understood, in its rigorous formulation within a specific choice of mathematical model (such as the bit model), as a statistical law of nature. In particular, it is not means as a supplement of the given laws of physics, but as a replacement74It would certainly be a very bad idea to try and use algorithmic idealism, or algorithmic probability, directly in physics. It will never be a good replacement in practice, it is only a very abstract theoretical (but remarkable) fact that it could be in principle.. Therefore, it is crucial to have a theorem that guarantees its consistency with the standard physical laws in the regime where they apply. This is essentially the regime of empirical science, i.e. of processes where a large amount of data is collected over time. The argumentation above intends to give a hint for why we should expect that this consistency is satisfied, and in the bit model, known results on Solomonoff induction and physical versions of the Church-Turing thesis make this a rigorous theorem.
6.2. The External World as an Emergent Approximate Phenomenon
Algorithmic idealism predicts this sort of consistency with physics, but all the above reasoning says is that agents who appear to be embedded in a simple probabilistic universe are also likely to make observations in the future that confirm this. But why should this former premise be the case in the first place, if algorithmic idealism is true? After all, one of the main methodological principles of algorithmic idealism is to drop the assumption that an agent is fundamentally embedded into an external world. So how can we understand why agents are likely to arrive at a self state that seems as if they are effectively embedded, such that the argumentation above applies (and shows that they will remain to be effectively embedded)?
One main insight shown for the bit model, but hopefully true much more generally, is the following somewhat technical result within AIT. Algorithmic probability measures such as \( \mathbf{M} \) are not computable. However, they may often behave very similarly as a computable measure \( \mu \), in particular if \( \mu \) is algorithmically simple. This may in particular be the case if, by chance, the previously observed bits \( x_1^n=x_1 x_2\ldots x_n \) happen to correspond to a typical result of the probability measure \( \mu \); intuitively, in this case, the following bits will also likely be distributed in accordance with \( \mu \). Intuitively, the statistical regularities present in \( x_1^n \) will tend to be preserved because this is what induction deems likely to be the case. This leads to a general tendency of “stabilizing” a very regular statistical behavior: one that is according to a simple computable measure \( \mu \). If this turns out to be the case, then the evolution of the agent’s self state will approximately be described by \( \mu \), and there will by definition exist75This is a statement of mathematical existence, not a claim of actual physical implementation, whatever the latter would mean. In particular, algorithmic idealism does not claim that there are actual machines that perform the computations which will naturally arise as external worlds for our experiences; these computations are in some sense extremely convenient (and hence meaningful) fictions. a computation, based on a short program that generates \( \mu \). To predict what happens to the agent, we may hence pretend that the agent is part of a computational process that generates its self state according to the computable distribution \( \mu \), and this process plays the role of an external world.
In the case of the bit model, the technical result that I mentioned can be described as follows (see Ref.76M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020). for the details):
“Inverse Solomonoff Induction”. Suppose that you observe one bit \( x_1,x_2,x_3,\ldots \) after the other, distributed according to algorithmic probability \( \mathbf{M}(b|x_1^n) \) (this is the formalization of algorithmic idealism’s Postulate 2 in the bit model). Suppose that \( \mu \) is any computable measure over the bit strings. Then, with \( \mathbf{M} \)-probability at least \( 2^{-K(\mu)} \), it holds $$\lim_{n\to\infty} |\mathbf{M}(b|x_1^n) -\mu(b|x_1^n)|=0\qquad (b\in\{0,1\}).$$ That is, for every computable measure \( \mu \), there is a positive probability that algorithmic probability (and hence the actual chances of what happens to the agent), conditioned on the previous observations, will converge to \( \mu \). Not all measures are equally likely, though. Colloquially, we can think of \( K(\mu) \) being small (probability \( 2^{-K(\mu)} \) being large) as saying that there is a probabilistic computational process that generates \( \mu \) which has a short program, i.e. is simple in this sense. It can be modelled as running on some machine with a dedicated part (for Turing machines77Algorithmic idealism does not tell you what the computational model is; all computational models can simulate each other and are hence algorithmically equivalent, up to qualifications such as “being prefix-free” which have direct impact on the set of all possible algorithmic probability distributions that these machines generate. But whether you, say, describe an algorithm in terms of a Turing machine or of a cellular automaton is completely up to you. In particular, algorithmic idealism does not claim that an agent’s external world should resemble any of our mathematical models that we happen to have accidentally introduced and studied in computer science., the output tape) that contains the self state \( x \) which evolves when the computation unfolds. As every computation of this sort, it starts in some fixed initial state, with a short program of length \( K(\mu) \) that tells the machine what to do. After this, it unfolds probabilistically, and it contains many other things in addition to the self state (for Turing machines, it would be other tapes, working memory etc.) such that the resulting evolution of the self state can be understood to arise from this in a “mechanical” manner.
Figure 3. If a bit string \( x \) (dark green, on the left) grows in length according to a computable measure \( \mu \), then we can imagine a corresponding computation that generates this string (for example modelled in terms of a monotone Turing machine). In this sense, we can pretend that \( x \) is embedded into a larger “external world” (the computation) whose evolution is the “mechanistic” cause for how the string changes over time. Similarly, what we experience and remember (dark green, on the right) unfolds over time in a way that admits an explanation in terms of an external world, i.e. a computable process that can be understood as the “mechanistic cause” of our self state’s evolution.
But this is a very good description of what we mean by our external world W: a larger process into which we seem embedded, and which seems to have once been in a simple distinguished state (the Big Bang) and then evolved probabilistically according to simple laws. We can reason about things in our external world (e.g., a brick falling towards my foot) and use this to construct mechanistic, causal explanations for the evolution of our self state (e.g., the sensation of pain and the observation that something red can be seen when I look down). The fact that our world is formally computable in some sense, and can hence colloquially be understood as a computation, is a well-known and widely discussed thesis that comes in different versions78J. Schmidhuber, Algorithmic Theories of Everything, Instituto Dalle Molle Di Studi Sull Intelligenza Artificiale (2000), arXiv:quant-ph/0011122; S. Lloyd, Programming the Universe: A Quantum Computer Scientist Takes on the Cosmos, Random House, New York, 2006..
Hence, the inverse Solomonoff induction result can be interpreted as saying that with probability at least \( 2^{-K(\mu)} \), you will find yourself effectively embedded into the world \( W \) pertaining to \( \mu \) that we have just described. That is, your first-person probabilities \( \mathbf{P}_{\rm 1st}(y|x)=\mathbf{M}(b|x) \) of what actually happens to you (where \( x=x_1^n \) and \( y=xb \)) will be very close to the “third-person probabilities” \( \mathbf{P}_{\rm 3rd}(y|x)=\mu(b|x) \) of how your representation in world \( W \) evolves. In the bit model, this will persist in the limit of \( b\to\infty \), that is, ad infinitum. In other formalizations of algorithmic idealism that admit “forgetting”, we expect this to be the case as long as the self state retains enough memory of previous observations that indicate that world \( W \) is a good explanation. But this will have to be demonstrated mathematically, which is the subject of ongoing work.
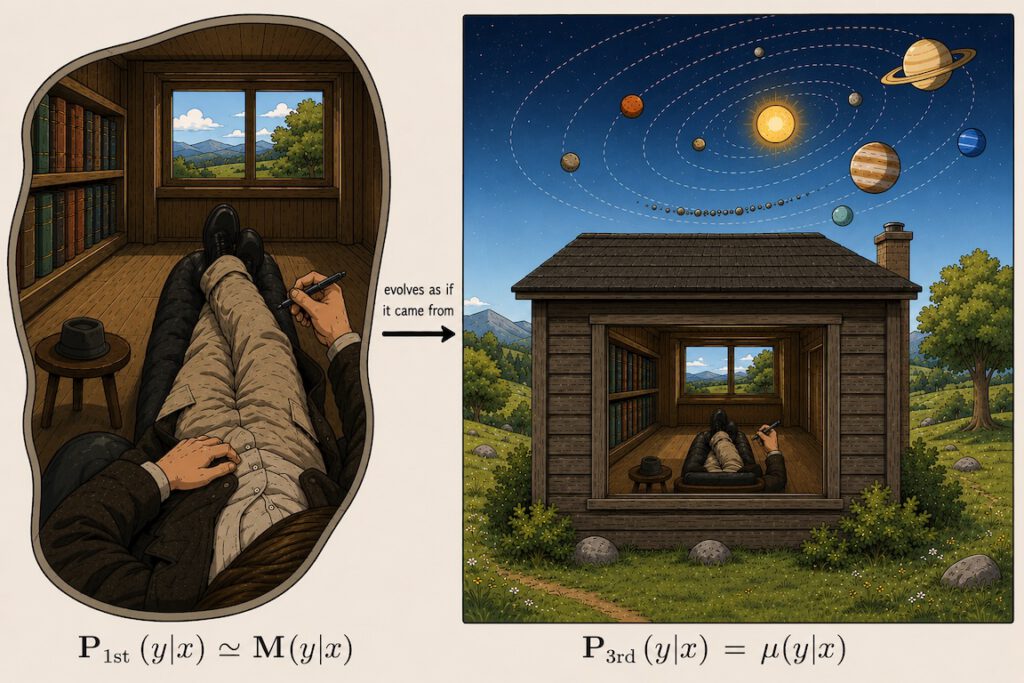
Consequently, you can pretend that you are currently effectively embedded into some world \( W \) (intuitively, until you have a dramatic loss of memory), even if you are fundamentally not. Which world \( W \) should you initially have expected to be in, had you been able to wonder? According to algorithmic idealism, the answer has not been predetermined. In the bit model, you could have said that algorithmically simpler worlds79In more detail, it is not only the world \( W \) that has to be simple, but also the specification of “your place in it”, since both are implied by a program that generates the resulting self state distribution \( \mu \)., i.e. ones with shorter program length \( K(\mu) \), are more likely, which seems to indicate that you should not be surprised to find yourself in a world that can be described in terms of a small set of mathematically simple physical laws. In particular, the picture that there is “one actually existing, realized world among all the infinitely many possible worlds” has to go, which implies a view similar to Lewis’ modal realism80D. Lewis, On the Plurality of Worlds, Wiley-Blackwell, 2001..
If our usual picture of reality is demolished, by what is it replaced? Similarly as quantum theory, algorithmic idealism does not tell you what reality is, it only tells you what it is not. What you should ask instead is: What is the fate of the self in algorithmic idealism? The answer will be very different from the one we expect of our usual picture of the world, and it will depend on the specific formal model of algorithmic idealism. Let me give you a hint of one possibility. Imagine a formalization of algorithmic idealism where the random walk on the self states is an ergodic Markov chain, then you are on an infinite journey on which you visit every self state infinitely often. You will sometimes land on a self state \( x \) with the property that \( \mathbf{P}_{\rm 1st}(y|x)\approx \mu(y|x) \) for a probability measure (or more general likelihood structure) \( \mu \) corresponding to some simple world \( W \). This will be the case for a few time steps if and only if \( W \) (up to predictively inessential modifications) is essentially the unique plausible explanation for \( x \) that would be found by universal induction. Hence you will find yourself effectively embedded into world \( W \) until some dramatic event happens that erases most of your memory, and you will effectively “fall out of the world”. After more random walking, you will land on another self state with a similar property, and you will find yourself embedded into another (probably simple) world \( W’ \) — and so on, ad infinitum.
6.3. More Than One Observer: Emergent Objective Reality…
The above argumentation may seem suspiciously solipsistic. I have described how an external world may emerge for a single agent, but what about other agents? Is algorithmic idealism committed to solipsism, in the sense that it postulates the existence of only a single observer? Recall that observers or agents are not fundamental elements of algorithmic idealism, but only momentary snapshots of their structure: the self states, which is similar to Parfit’s concept of a person stage. Hence, it does not make sense to ask “how many agents” there are in algorithmic idealism, and we have to be more precise about the question that we are actually asking when raising this objection.
Here is a meaningful question to ask. Consider an agent (say, you) that currently happens to find itself effectively embedded into a simple computable probabilistic world \( W \) — we already understand how and why this can happen. Now, suppose that you identify something in your external world (“my friend Bob\(_{\rm 3rd} \)”, where the notation indicates that you refer to him from a third-person perspective) that carries a representation of some self state \( x \), evolving over time in a way that is broadly consistent with the specific chosen formalization of Postulate 2 (in the bit model, for example, it would have to contain a bit string of non-decreasing length without any erasure or “forgetting”). Perhaps \( x \) encodes Bob\(_{\rm 3rd} \)’s brain state, and you would intuitively like to conclude that there is a first-person perspective associated to it, some actual “self” Bob\(_{\rm 1st} \) that is associated to \( x \). To clarify what we mean by this, let us compare two probability distributions81For the sake of the argument, we assume that the “likelihood” claims of Postulate 2 are formalized in terms of a probability distribution (or several ones, as it is the case in the bit model). Other choices are certainly possible, and my hope is that the gist of this argument applies more broadly.:
- the probability \( \mathbf{P}_{\rm 1st}(y_1,\ldots,y_m|x) \) that \( x \) will change into \( y_1,y_2,\ldots,y_m \) over the next time steps according to algorithmic idealism’s Postulate 2;
- the probability \( \mathbf{P}_{\rm 3rd}(y_1,\ldots,y_m|x) \) that determines how the information content of Bob\( _{\rm 3rd}\) evolves next according to the probabilistic evolution of world \( W \).
These probabilities describe the distributions of future self states \( y_1,\ldots,y_m \) of an agent that is currently in self state \( x \) (Bob\( _{\rm 1st}\)), and of the future recordings in the piece of matter in your world that you call Bob\( _{\rm 3rd} \). Intuitively, we assume that the first- and third-person descriptions align — indeed, the prospect that they would not align seems terrifying, because it would indicate that your interaction with the other agent (not just with the piece of matter) would in some sense only be an illusion. In particular, this requires \( \mathbf{P}_{\rm 1st}\approx \mathbf{P}_{\rm 3rd} \): if you have a high chance of seeing your friend Bob\( _{\rm 3rd} \) see the sun rise tomorrow, then Bob\( _{\rm 1st} \) will indeed have a high chance of seeing the sun rise tomorrow. This implies in particular that we can causally affect Bob\( _{\rm 1st} \) by interacting with Bob\( _{\rm 3rd} \) (say, Bob will be happy because you hug him), as long as we can have an effective notion82Even in classical mechanics, we have an effective notion of intervention, e.g. by talking about deciding to set particular initial conditions when running an experiment. Determinism (or lawlike probabilistic behavior) should not be seen as a restriction on the possibility of free will as a higher-level phenomenon, as has been argued by compatibilists such as Daniel Dennett (D. C. Dennett, Freedom Evolves, Penguin Group, New York, 2003). of intervention in world \( W.\) In a physicalist worldview, this is of course a triviality, but in algorithmic idealism it is not.

Indeed, algorithmic idealism predicts that \( \mathbf{P}_{\rm 1st}\approx\mathbf{P}_{\rm 3rd} \) under conditions that we expect to be satisfied when we encounter ordinary observers in our everyday lives, and in this sense it predicts the emergence of objective reality. This can be seen as follows. Due to Postulate 2, \( \mathbf{P}_{\rm 1st} \) is exactly what the method of universal induction \( M \) would give you. But similarly as in the Earth example above, if \( x \) contains enough data (think about a pretty accurate description of all functionally relevant details in your friend Bob’s brain), then a good method of induction is expected to extract an exhaustive description of all relevant physical laws of world \( W \) from it, and of all relevant facts of Bob\( _{\rm 3rd} \)’s environment — and hence is expected to predict that this self state evolves as if it were embedded into world \( W \). In other words, this method of inductive inference should approximately lead to predictions that agree with \( \mathbf{P}_{\rm 3rd} \). Thus, according to Postulate 2, what happens to Bob from his perspective (via \( \mathbf{P}_{\rm 1st} \)) will be in agreement with \( \mathbf{P}_{\rm 3rd} \): in this sense, you share the world \( W \) with Bob.
In the bit model, the correctness of this argumentation is indeed a theorem: the evolution of your friend Bob’s self state according to world \( W \) is \( \mathbf{P}_{\rm 3rd} \), which is a computable measure because the world \( W \) is computable. Hence, due to some variant of Eq. \( \eqref{eq2} \), algorithmic probability (or rather its normalized version \( \mathbf{P}_{\rm 1st} \)) must converge towards it with worldly probability one, in the limit of more and more bits that Bob learns.
Returning to the question of the beginning of this section, this result suggests that algorithmic idealism should not be considered solipsistic: if Alice points at some piece of matter (or structure) that encodes some self state \( x \) in her world, then she can in many cases conclude that “somebody is really at home” in this structure in some sense. This is because if \( \mathbf{P}_{\rm 1st}\approx\mathbf{P}_{\rm 3rd} \), the probabilistic evolution of this structure in Alice’s world (via \( \mathbf{P}_{\rm 3rd} \)) faithfully represents the evolution of some Bob’s first-person perspective (via \( \mathbf{P}_{\rm 1st} \)), even if Alice interacts with it.
More formally, the question “how many agents are there?” (one, many, infinitely many?) is not well-defined in algorithmic idealism, because only self states and their probabilistic transitions are fundamental and well-defined, while the notion of “agent” (or a “self”) is a pragmatic and vague term that will only sometimes work as expected. More fundamentally, the metaphysical basis of even raising the charge of solipsism is denied to apply in algorithmic idealism: in this view, there are infinitely many self states, they certainly all exist mathematically, but “physical existence” is not a meaningful property that a given self state could lack or possess (the trivial observation notwithstanding that a given observer may only see some of these self states in its own emergent external world). While algorithmic idealism hence rejects the basis of the usage of the word “exist” in the question “Do other minds exist?”, the in spirit best answer to this formally undefined question is to say that algorithmic idealism suggests the existence of all possible minds in some sense, and hence is maximally non-solipsistic.
6.4. … and Its Limitations: Probabilistic Changelings and Boltzmann Brains
The result of the previous subsection hinges on an important assumption: that the other agent Bob’s self state is complex enough to make universal induction infer Alice’s probabilistic world W from it, so that it is also Bob’s world. If this is not the case (in particular, in the bit model, if \( K(x)\ll K(\mathbf{P}_{\rm 3rd}) \), where \( x \) is Bob’s current self state, see83M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020).), then we will in general have \( \mathbf{P}_{\rm 1st}(y|x)\not\approx \mathbf{P}_{\rm 3rd}(y|x) \). Then we have an extremely counterintuitive phenomenon: the agent will be a probabilistic changeling84In earlier work such as M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020), probabilistic changelings have been called probabilistic zombies, but this seems to convey the wrong types of intuitions, hence the change of name.. In medieval European superstition, the changeling was an infant that was foisted on a recent mother by a demonic being in exchange for her own child with the intention of harassing and harming people; while the mother thought she would have her own child at home, it was actually some other being. To see why this is sort of a fitting (albeit limited and morbid) analogy, consider the following example.
As before, suppose that you are currently effectively embedded into some simple probabilistic world W (you probably are as you are reading this), but suppose it is the year 2178 and we have science fiction technology: a computer on your desk simulates another simple probabilistic world \( W’ \) that has given rise to the evolution of intelligence. For a while, you have been observing one of the simulated beings, which you call Charlie\( _{\rm 3rd} \). Given the momentary self state \( x \) encoded into Charlie\( _{\rm 3rd} \), you know that it is complex enough to make the universal method of induction infer world \( W’ \) from it85Note that the method of induction will infer world \( W’ \) up to predictive equivalence, i.e. it might also infer world \( W \) with the running simulation. The goal of inductive inference is to predict the future, not to explain it.. Hence, you conclude that whoever is that self state (colloquially, you associate the name Charlie\( _{\rm 1st} \) to this agent, even though you know that algorithmic idealism has no fundamental notion of agent) will indeed continue to experience world \( W’ \); formally, this means that \( \mathbf{P}_{\rm 1st}(y|x)\approx \mathbf{P}_{\rm 3rd}(y|x) \). In other words, Charlie\( _{\rm 3rd} \) is an accurate representation of Charlie\( _{\rm 1st} \) — in this sense, Charlie\( _{\rm 1st} \) is “really at home” in the simulation.
But now you decide to take a malicious action: you intervene in the simulation and arbitrarily replace some of the features in Charlie’s environment. Perhaps you place a giant, pink, simulated rabbit in a spacesuit next to Charlie’s house, without anyone in the simulation being able to explain where it comes from. This will dramatically alter the future probabilities \( \mathbf{P}_{\rm 3rd} \) for Charlie\( _{\rm 3rd} \) (implying, for example, high probability for Charlie\( _{\rm 3rd} \) displaying strong surprisal soon). However, it cannot alter the probabilities \( \mathbf{P}_{\rm 1st} \) which will continue to determine Charlie\( _{\rm 1st} \)’s future, since these only depend on Charlie’s self state \( x \) which you have kept intact. In some sense, you have replaced simple world \( W’ \) on your desk with some other, much more algorithmically complicated world \( W” \), but Charlie\( _{\rm 1st} \) will probably continue to experience living in world \( W’ \). While you will continue to observe Charlie\( _{\rm 3rd} \) in the simulation, your beloved Charlie\( _{\rm 1st} \) is gone — and has been replaced by an unlikely Changeling\( _{\rm 1st} \) who is now realized in Charlie\( _{\rm 3rd} \).
You may now feel sad because you really liked Charlie\( _{\rm 1st} \) and she is gone, but it would be wrong to think that Changeling\( _{\rm 1st} \) is somehow an unconscious zombie of some sort. If you thought that Charlie\( _{\rm 1st} \) is conscious, then you have no reason to doubt that Changeling\( _{\rm 1st} \) is conscious too, and she will very strongly feel that her past was accurately described by Charlie\( _{\rm 3rd} \) previously, and hence she will feel like a legitimate successor of Charlie\( _{\rm 1st} \) as you knew her before the malicious rabbit event. It is simply that an agent on its random walk on the self states will less often end up in world \( W” \) because it is algorithmically more complicated; it corresponds to a path less trodden in computable possibilityspace. We have a counterintuitive situation where chances of events are strongly agent-relative, and where the notion of “agent” gets dissolved in ways that are even more enigmatic than, say, in Everettian quantum theory. But even if this phenomenon is extremely counterintuitive, it is mathematically consistent.

This curious phenomenon is at the heart of algorithmic idealism’s resolution of exotic puzzles such as the Boltzmann brain problem. A mathematically and information-theoretically detailed discussion of this problem within the bit model is given in Ref.86M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)., and about its relation to Restriction A in Ref.87C. L. Jones and M. P. Müller, On the significance of Wigner’s Friend in contexts beyond quantum foundations, Quantum 10, 2147 (2026).; here we only sketch the main idea of a treatment that should apply to all models of algorithmic idealism. Suppose that the world W into which you happen to be effectively embedded is indeed combinatorially large, and you know that there must be many more Boltzmann brains than ordinary ones. Consider some ordinary brain OB and some Boltzmann brain BB that both encode your current self state x. Recall that according to algorithmic idealism, it would be a category mistake to say “I am the OB” or “I am the BB”, since you are simply your self state \( x \), and this self state is realized or represented both in the OB and in the BB. Regardless of what happens to the OB or the BB, what happens to you is characterized by \( \mathbf{P}_{\rm 1st}(y|x) \). The third-person perspective tells you that the OB and the BB are going to evolve very differently in the near future according to world W, that is, \( \mathbf{P}_{\rm 3rd}^{\rm OB}(y|x)\not\approx \mathbf{P}_{\rm 3rd}^{\rm BB}(y|x) \). But then, these probabilities cannot both be approximately equal to \( \mathbf{P}_{\rm 1st}(y|x) \), and the ordinary brain or the Boltzmann brain (or both) must become a probabilistic changeling.
In fact, it will be the Boltzmann brain who will become the probabilistic changeling, while \( \mathbf{P}_{\rm 1st}(y|x)\approx\mathbf{P}_{\rm 3rd}^{\rm OB}(y|x) \). An explicit technical demonstration of this in the bit model is given in Ref.88M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020).. Intuitively, this is again due to Postulate 2: what happens to you next is what a universal method of induction would predict. Inductive inference tends to extrapolate regularities in your current self state (perhaps contained in your memory of what you interpret as a large number of past observations) into the future, including the pattern of looking as if you had been immersed in a low-entropy planet-like environment with a myriad of regularities. In particular, for the bit model, \( \mathbf{P}_{\rm 1st}(y|x) \) is a version of algorithmic probability, and its value being large means essentially that a small amount of algorithmic information is needed to compute \( y \) from \( x \), regardless of how many instances or copies of \( x \) there might be in the external world that is inferred from \( x \).
In summary: even if you have reasons to believe that your external world contains many more Boltzmann brains than ordinary brains, what will happen to you next will most likely still be what you would expect if you believed that you are an OB, not a BB. As explained above, algorithmic idealism denies that the question “Am I an ordinary brain or a Boltzmann brain?” makes literal sense as it stands: you are your self state, and not one of its realizations. But it predicts that your future experiences will with overwhelming probability confirm “business as usual on Earth” rather than Boltzmann brain flamboyancy — regardless of the actual number of Boltzmann brains in the universe.
7. Example: How to Think About the Simulation Hypothesis
The following five propositions seem to jointly entail that you are probably in a simulation:
- It is possible to simulate conscious minds.
- Technological progress will not stop any time soon.
- Many advanced civilizations do not destroy themselves.
- Many advanced civilizations want to run simulations.
- If there are many more simulated beings than unsimulated, you are probably simulated.
The argument for this entailment claim is well-known89N. Bostrom, Are We Living in a Computer Simulation?, Philos. Q. 53(211), 243–255 (2003). and will not be rehearsed here. It is relevant here because if one is a physicalist, then it is not at all clear which proposition should be rejected to avoid the conclusion.
The simulation hypothesis is similar to the Boltzmann brain hypothesis. In the latter, a set of plausible physical assumptions leads to the conclusion that most minds are Boltzmann brains; in the former, a set of plausible technological assumptions leads to the conclusion that most minds are simulations. It might seem that the latter conclusion is not so bad to embrace90D. Chalmers, Reality+. Virtual Worlds and the Problems of Philosophy, W. W. Norton, 2022.. But in fact it raises similar issues to the former91E. Schwitzgebel, Let’s Hope We’re Not Living in a Simulation, preprint (2024)., since the most common simulations might be ones that are suddenly and unexpectedly shut off.
But it is not clear which of the five propositions one should reject. From a traditional physicalist perspective, Proposition 5 is difficult to deny as it seems based on a fairly innocent principle of indifference. Proposition 4 is very difficult to deny, since even if some of our descendants choose not to simulate conscious minds given the opportunity, surely many still will. Denying propositions 3 or 2 seems awfully pessimistic. That leaves us with Proposition 1. Some do deny it and argue that consciousness is based in biology, and so cannot be realized in silicon92N. Block, Troubles with functionalism, in C. W. Savage (ed.), Perception and cognition: issues in the foundations of psychology, University of Minnesota Press, Minneapolis, 1978.. However, this is a minority view that conflicts with functionalism in the Philosophy of Mind as well as prominent neuroscientific theories such as Global Workspace Theory and Integrated Information Theory.
Algorithmic idealism does not change the assessment of the technology-related Propositions 2, 3 and 4 as compared to the traditional physicalist. But what about Proposition 1? To approach the answer, let us introduce another proposition:
- It is possible to give biological birth to conscious minds.
Algorithmic idealism claims that
Propositions 1 and I have identical truth values. In particular, they are both true if the terms in these propositions are understood correctly.
Traditional physicalists who are also functionalists about consciousness would arguably agree on this. However, those scholars and algorithmic idealists would have different reasons for declaring 1) and 1’) equivalent. Here is what they could say:
Physicalist & functionalist: “Biological birth” or “starting a simulation” are events that give rise to a conscious being. That is, they are the material causes of this specific instance of consciousness coming into actual existence at this time and place in the universe, and this specific conscious being would have never existed if this specific event (or another, very similar event) had not happened.
Since biological and simulated minds are functionally equivalent, there is no reason to speculate whether 1 might be true but I might be not.
Algorithmic idealist: You are your self state, and if you are conscious then this is a property of your self state. Consequently, and more generally, all self states that deserve being called “conscious” exist as mathematical structures (as all unconscious ones do), and they experience transitions according to Postulate 2, regardless of whether they are actualized in our world. Hence, “giving birth” or “starting a simulation” do not create a self state, but they create material conditions that represent it.
If \( x \) is not a probabilistic changeling (recall Section 6), then it is in some sense correct to say that the material conditions so created have introduced an instance of consciousness into our world. But this should not be understood as “having created” a conscious being that would not have otherwise existed, but rather as having enabled the conditions to “share the world” with it. The consequences of birth or the start of the simulation are structural: all probabilities for what happens to the material conditions that represent \( x \) (described by \( \mathbf{P}_{\rm 3rd}(y|x) \)) are now very close to the probabilities for what happens to \( x \) from its private perspective (described by \( \mathbf{P}_{\rm 1st}(y|x) \)).
In particular, algorithmic idealists and physicalists who are also structuralists agree on 1 being true, even though they understand the meaning of this proposition differently.
Finally, what about Proposition 5? We will see that there is, finally, disagreement between the two camps, for similar reasons as in the Boltzmann brain problem. Let us begin by describing why physicalists may be inclined to think that 5 is true, even though they perhaps should not if their aim is to be carefully consistent overall.
Consider a universe that is simulation-dominated, i.e. there exist many more simulated than biological conscious beings. Physicalists would say that this description captures all there is to say about the physical facts, and all meaningful beliefs to be held are beliefs about facts of the world. But then, almost by definition, physics cannot tell you what you should believe about being either one or the other — we have an instance of Restriction A, as introduced in Section 3. In some situations in thermodynamics, it turns out that principles of indifference lead to empirically successful predictions, and they seem sort of intuitively plausible (and you can waive your hands and appeal to maximum entropy or symmetry principles or whatever). Physicalists might want to refer to such arguments, or simply to the feeling that maximal ignorance is the best option if you must choose to believe something when, actually, you shouldn’t. Hence, as the argument goes, if the universe is simulation-dominated, then you should believe that you are in a simulation.
Algorithmic idealism disagrees, and does so along similar lines as in the Boltzmann brain problem. First of all, it denies that the statement “I am actually contained in a simulation” is, as a factual claim, meaningful. You are your self state \( x \), and you are fundamentally unembedded, even though \( x \) is represented in many possible computable worlds, and in many simulations running in those worlds.
However, a suitably operationalized version of the statement above does make sense in some cases. Namely, which of these representations of your self state \( x \) (if any) tracks more accurately your actual first-person probabilities? For example, you can think of two possible scenarios, which you might colloquially want to describe as follows (though algorithmic idealism warns you that you should not unterstand these colloquial descriptions too literally):
- You will continue to experience (what you think is) “base reality” as usual (more generally, your complete self state, including all its unconscious aspects, will probabilistically evolve as it would in base reality).
- In a few seconds from now, you make some unusual simulation-indicating experience. (For example something like this: the Moon suddenly disappears, and is replaced by a face of some strange creature that begins to laugh and explains that you are in a simulation, and that it is its actual creator.)
Algorithmic idealism has something to say about the relative probabilities of these scenarios: whatever induction predicts is more likely, regardless of the number of representations that you may count. Comparing these two very specific scenarios, we would conclude that the first one is more likely. Note that the same argumentation applies not just to a specific choice of surprising event (such as the above), but to the general event that something non-base-reality-conforming will happen, which is predicted to be unlikely. Clearly, this intuitive conclusion has to be rigorously proven, given a concrete mathematical model of algorithmic idealism. The calculation in Ref.93M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020). for the Boltzmann brain problem should yield some guidance on how to do this in the bit model.
In summary, algorithmic idealism rejects Proposition 5: even if there are many more simulated beings than unsimulated ones, this does not imply that you should think that you are probably simulated. It is not the number of the realizations that is relevant, but what a universal method of inductive inference would predict based on your current self state. Note that this is not an epistemic statement, i.e. merely a description of what some method of induction gives you, but a lawlike claim that you will actually probably not observe any unusual simulation-indicating experiences in the future.
It is important to note that algorithmic idealism does not tell you without further qualification that you are probably not simulated. For instance, it claims that there is no ontological difference between the following two claims:
- You will continue to experience base reality because you are actually embedded in base reality.
- You will continue to experience base reality because you are embedded in a very accurate simulation of it.
According to algorithmic idealism, you are unembedded, and hence both statements are equally meaningless: their formulation contains a category mistake. In particular, there is no sense in which any one of them would be “more correct” than the other.
Recall that algorithmic idealism predicts that agents will often find themselves effectively embedded into some computable world \( W \): pretending that you are embedded will accurately track your first-person chances. It is conceivable that your self state is represented in \( W \) within something that you might call a computer simulation running in \( W \). However, if this simulation (call it \( W’ \)) is isolated — that is, if it has been programmed and keeps running without any intervention from the outside — then it is equally correct to pretend that you are embedded into standalone world \( W’ \) (without the world \( W \) and computer running it). Hence, the only meaningful instance in which algorithmic idealism gives you an effective embedding specifically into a simulation is in cases where the simulation is not isolated, but information from the external world \( W \) leaks into the simulation (for example by intervention). This distinction, together with further implications for the simulation of agents (including ethical questions raised by Bostrom94N. Bostrom, Superintelligence: Paths, Dangers, Strategies, Oxford University Press, Oxford, 2014.) is discussed in more detail in Ref.95M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)..
As a final remark, let us get back to a comment of the beginning of this section that articulated a particular worry against the simulation hypothesis: most common simulations might be suddenly and unexpectedly shut off. Does this worry not indicate a fundamental difference between the two scenarios a. and b. above? Algorithmic idealism denies this. Recall the “changeling” example of Section 6, where you run an isolated simulation of a world \( W’ \) which contains an agent Charlie\( _{\rm 3rd} \). Suppose that you decide to shut the simulation down. This means that Charlie\( _{\rm 3rd} \) (the corresponding pixels shown on your screen, or the pattern in the computer memory, if you wish) ceases to exist. However, Charlie\( _{\rm 1st} \)’s probabilities \( \mathbf{P}_{\rm 1st}(y|x) \) of her future observations \( y \) are essentially96In the case of the bit model, it should be considered to be modified by an unimaginably tiny amount: among all supporting explanations for predicting \( y \) according to \( W’ \)-probability, the contribution coming from “world \( W \) simulating \( W’ \)” disappears, and hence universal induction may be ever so slightly less inclined to converge to this particular probability value. unaltered by this: the universal method of induction (mentioned in Postulate 2) will continue to infer that world \( W’ \) is essentially the best explanation for Charlie\( _{\rm 1st} \)’s self state, and hence Charlie\( _{\rm 1st} \) will continue to experience world \( W’ \). According to algorithmic idealism, shutting down a closed simulation does not “kill” its inhabitants, but it leaves them essentially unaffected. Intuitively, your simulation is more of a “movie” than a “zoo”, and hence its destruction does not affect its protagonists. For science fiction fans, this has amusing parallels with the “dust theory” described in Greg Egan’s Permutation City97G. Egan, Permutation City, Night Shade Books, 2014..
8. Conclusions
I have presented an approach to the Foundations of Physics, tentatively called algorithmic idealism, which declares the first-person perspective fundamental. Essentially, it is the question of “what will probably happen to me next?” that is taken to be fundamental, rather than the question of “what is the case in the world?”. Despite its name, high-level and vague concepts such as agents, consciousness or belief do not play any fundamental role in algorithmic idealism, and its two postulates admit several possible rigorous mathematical formalizations, i.e. a class of concrete theories. One preliminary formalization, the bit model, has been presented in earlier work98M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)., which also contained formal proofs of many of the conceptual arguments that I have put forward here about what to expect from an approach like this: the emergence (not exactly, but to good approximation!) of a simple, probabilistic, computable external world into which the agent seems to be embedded, and of a notion of objective reality; the dissolution of enigmas such as the Boltzmann brain problem, Parfit’s teletransportation paradox, or the computer simulation of agents; and novel phenomena such as probabilistic changelings, implying a particular agent-dependency99I wholeheartedly and passionately oppose attempts to read this as supporting pseudo-spiritual nonsense. In everyday life and almost all situations in physics, facts are observer-independent. Claims are true or false, regardless of who expresses them (A. Sokal and J. Bricmont, Fashionable Nonsense: Postmodern Intellectuals’ Abuse of Science, New York: Picador, 1999), and truth exists and is observer-independent. The sort of agent-dependency that I am describing here is more of the sort of observer-dependency of lengths and time durations in special relativity: hard mathematical relations, rigorously formalized, and independent of what we wish, feel or believe. of facts and their likelihood.
By construction, the predictions of algorithmic idealism agree with those of our physical theories in standard laboratory situations if a suitable physical version of the Church-Turing thesis is true. Indeed, algorithmic idealism is constructed in the spirit of empiricism: no insights of any kind into the ontology of the world are directly sought, and essentially all human preconceptions about metaphysics are demolished on the way (or, rather, declared to be only useful models that sometimes give approximately the right answers). Rather than asking what the world is like, the sole goal of this approach is to get the phenomena right. In this sense, it intends to represent a minimal extension of the usual methodology of physics into new territory: from the regime of intersubjective experiments, where everybody can learn about the results, to private experiments for which a third-person view or prediction “from the outside” is in principle unavailable.
The mere possibility (even if considered unlikely) that some aspects of algorithmic idealism are closer to the truth than our standard view hints at a surprising lack of imagination in the way we look at some essential questions of humanity. Should humanity colonize the galaxy in order to make a large number of conscious lives possible that would not otherwise have existed100T. Ord, The Precipice. Existential Risk and the Future of Humanity, Bloomsbury Publishing, 2020.? Arguments in favor of this typically implicitly assume a particular metaphysics of “one single real world among infinitely many possible ones” that has already been criticized by Lewis101D. Lewis, On the Plurality of Worlds, Wiley-Blackwell, 2001. and that is rejected by algorithmic idealism. Does shutting down a computer simulation terminate its simulated conscious beings102E. Schwitzgebel, Let’s Hope We’re Not Living in a Simulation, preprint (2024).? This usually seems to be taken as obviously true, but algorithmic idealism claims that this is not generally the case, and that the answer will depend on how much information from the outside world is fed into the simulation. But if we do not understand what to say about the simulation of agents, how can we be so sure we understand death (recall Section 1)? The mere reason why we consider the view of transitioning into an infinite-duration unconscious “muted state” as the only scientifically plausible possibility may be that we have so far only seen alternatives promoting pseudo-spiritual nonsense and religious wishful thinking, and that we want to signal how serious and trustworthy we are by not even addressing the question.
These examples also demonstrate that algorithmic idealism is not merely a theory of how agents can best predict their future observations, but a radically new approach to physical reality. If it were simply some sort of theory of epistemology, then what will actually happen to an agent would be determined by the (in general unknown) physical world in which the agent would operate. In contrast, algorithmic idealism denies that the agent is fundamentally embedded into some world, and grounds whatever will happen to the agent on its self state alone. This counterintuitive starting point allows it to formulate a law (Postulate 2) which is meant to express how an agent’s fate is determined in mundane but also truly exotic situations, such as simulation and multiplication scenarios, and it makes very counterintuitive predictions (such as the possibility that agents may “fall out” of the world into which they are effectively approximately embedded, or the notion of probabilistic changelings). These predictions would not only be impossible to obtain in an epistemic approach (because, as we discussed via Restriction A, third-person claims about the world have nothing to say about first-person chances in, say, duplication scenarios), but they outright contradict the assumption of an agent that is embedded into some given but unknown world. This also indicates a clear separation from operational theories103B. Coecke and A. Kissinger, Picturing Quantum Processes, Cambridge University Press, Cambridge, 2017. as they are often formulated in the quantum information theory context: while these theories also often feature agents and their observations (such as Alice and Bob in a communication scenario), these agents are assumed to be embedded into a joint physical system (external world) that mediates their communication and observations. In algorithmic idealism, on the other hand, this external world is not postulated a priori, but an emergent statistical phenomenon, and so is the intuitive idea that Alice and Bob share the same physical world.
In summary, algorithmic idealism was not constructed with the intention to say anything directly about reality. However, the methodological starting point to ignore the usual realist assumptions led to a formulation which indeed admitted novel predictions that are not otherwise available, but at the same time made it incompatible with the received view of physical reality, and thus distinct from existing epistemic or operational approaches.
There are two main open technical problems for algorithmic idealism, and these turn out to be related. First, the bit model of Ref.104M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020). has to be replaced by a better mathematical formalization, and this is currently work in progress. Essentially, the bit model precludes the possibility of “forgetting”, which is unmotivated, unrealistic, and an artefact of the way that Solomonoff induction has been formulated in algorithmic information theory.
Second, a successful formalization of algorithmic idealism should predict some phenomenal aspects of quantum theory. Clearly, quantum theory is one of the main motivations for algorithmic idealism, as explained in Section 2. Moreover, if its probabilities of events are fundamentally agent-relative, then this already resembles a phenomenon that is sometimes considered genuinely quantum (as in the extended Wigner’s friend scenario105K.-W. Bong, A. Utreras-Alarcón, F. Gharafi, Y.-C. Liang, N. Tischler, E. G. Cavalcanti, G. J. Pryde, and H. M. Wiseman, A strong no-go theorem on the Wigner’s friend paradox, Nat. Phys. 16, 1199–1205 (2020). of Section 3). It also hints at the possibility that the resulting description of an agent’s external world may have the feature that not all potential events fit into a joint Kolmogorovian probability distribution, a fundamental structural element of quantum theory106A. Fine, Hidden Variables, Joint Probability, and the Bell Inequalities, Phys. Rev. Lett. 48, 291 (1982). which is necessary (though not sufficient) for many of its phenomena. The main goal should be to reconstruct107M. P. Müller, Probabilistic theories and reconstructions of quantum theory, SciPost Phys. Lect. Notes 28 (2021).; L. Hardy, Quantum theory from five reasonable axioms, arXiv:quant-ph/0101012 (2001).; B. Dakić and Č. Brukner, Quantum theory and beyond: is entanglement special?, in Deep Beauty: Understanding the Quantum World through Mathematical Innovation (ed. H. Halvorson), Cambridge University Press, Cambridge, 2011, arXiv:0911.0695; L. Masanes and M. P. Müller, A derivation of quantum theory from physical requirements, New J. Phys. 13, 063001 (2011); G. Chiribella, G. M. D’Ariano, and P. Perinotti, Informational derivation of quantum theory, Phys. Rev. A 84, 012311 (2011). phenomena that are genuinely quantum, such as the violation of Bell inequalities together with compliance with the no-signalling principle108J. Barrett, N. Linden, S. Massar, S. Pironio, S. Popescu, and D. Roberts, Nonlocal correlations as an information-theoretic resource, Phys. Rev. A 71, 022101 (2005)., or the possibility of performing BQP-complete computations in polynomial time109S. Aaronson, NP-complete problems and physical reality, ACM SIGACT News 36(1), 30–52 (2005), arXiv:quant-ph/0502072.. Indeed, a potential explanation for the former phenomenon in models of algorithmic idealism that admit forgetting has been sketched in Ref.110M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020)., and is depicted in Figure 4, but it needs further elaboration. Note that it is not enough to point at mathematical elements (such as complex numbers, “wave functions” or evolution equations) that resemble mathematical elements of quantum theory, as is done in some approaches. Instead, the main question is whether the statistical results of experiments are predicted to behave in genuinely nonclassical ways, and any claims of saying something about this must engage with the insights from research on the foundations of quantum theory. In particular, its ability (or inability) to predict aspects of quantum theory is an important opportunity to test algorithmic idealism, and this alone suggests that it would be methodologically wrong to build the quantum formalism into algorithmic idealism by construction.
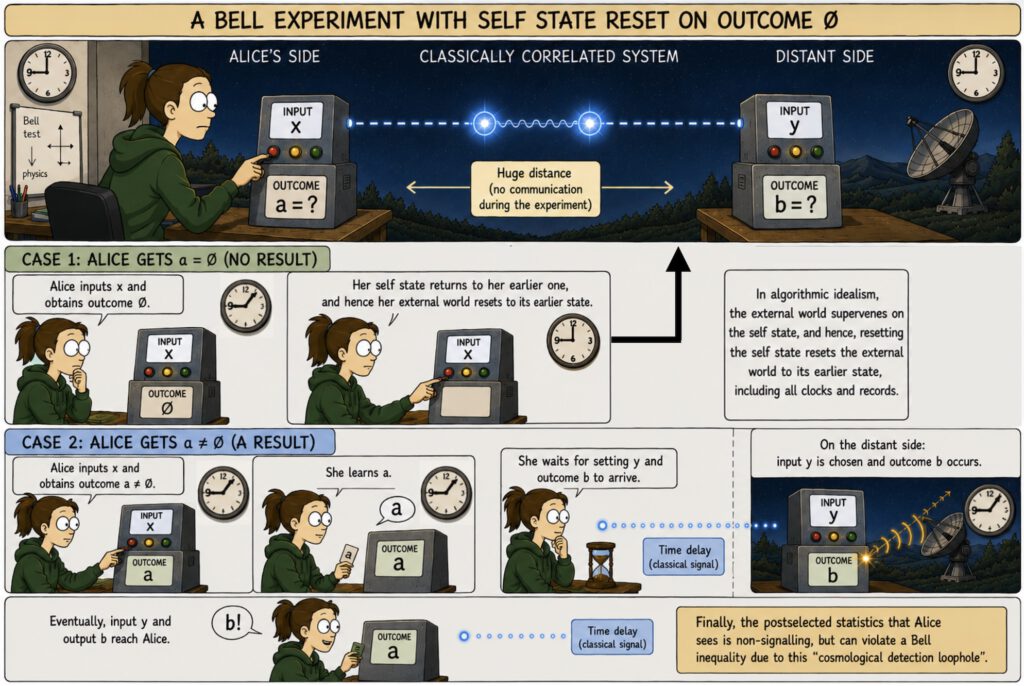
Figure 4. A sketch how non-signalling but Bell-inequality-violating statistics \( P(a,b|x,y) \) are naturally predicted by algorithmic idealism, assuming that the emergent external world carries some locality structure which admits the definition of a Bell experiment. This has been described in Ref.111M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020).. The main idea is that the external world ultimately supervenes on the self state, which implies some surprising statistical consequences in the case of “erasure” of self state information (for example, if the probability of erasure is correlated with a distant random variable). In this case, the resulting phenomenon resembles Huw Price’s suggestion of explaining Bell correlations as selection artefacts112H. Price, Bell correlations and selection bias, arxiv:2605.00406.. But to actually obtain something like this as a prediction of a.id., one would first need to solve the “no erasure” problem described in the FAQ.
There are several other elements of algorithmic idealism that need further elaboration. As a simple example, its reference to a “physical Church-Turing thesis” has to be further fleshed out: what exactly is assumed here about the computability of our physical world? Note that only something much weaker than Zuse’s thesis113K. Zuse, Rechnender Raum, Friedrich Vieweg u. Sohn, Wiesbaden, 1969. and even weaker than Deutsch’s version114D. Deutsch, Quantum theory, the Church-Turing principle and the universal quantum computer, Proc. R. Soc. (London) A 400, 97–117 (1985). is needed such that algorithmic idealism is guaranteed to be consistent with physics: the method of induction \( M \) that is used in the formalization of Postulate 2 should be successful in our physical world. In the bit model, \( M \) is Solomonoff induction. In a nutshell, for it to be successful, we need the existence of an algorithm which, given a description of an experiment with discrete outcomes, computes the probabilities of all possible results. This seems to be a rather harmless presumption which neither assumes that our physical world is discrete nor that it is deterministic. However, the details of this assumption have to be worked out, and the claim that this applies to our current theories has to be verified in detail, while keeping in mind that the method of induction will change under a modification of the formalization of Postulate 2.
As an epilogue, let us finally return to the scenario of Section 1: what should we answer the patient’s desperate question, under the unlikely assumption that algorithmic idealism is true? Will it “wake up” in the computer simulation or not? Given that we do not know the patient’s self state, the details of the simulation, and that we do not even rely on a particular formalization of Postulates 1 and 2, we can only attempt some sort of “rule of thumb” answer based on general principles of algorithmic idealism: you are your self state, and there is no need to be realized in a material object in what you currently experience as your external world in order to be “awake”. So yes, perhaps you will experience the simulated environment. But then, the simulation should be algorithmically simple, or otherwise the transition will be unlikely — a complicated paradise-like environment tailored to your needs will probably not do the job. So, in the end, maybe you would not even have needed to spend your money, because the simulated world exists mathematically regardless of what AfterMath has been doing. At the very least, you do not have to pay AfterMath to prevent them from shutting it down later. But to say more, one would need a detailed mathematical model of algorithmic idealism and a lot more work.
The rule of thumb answer can hence perhaps be summarized in two words: be hopeful.
Acknowledgments
I am grateful to Kelvin McQueen for many helpful and stimulating discussions, and in particular for his earlier contributions to what has become Section 7 of the present paper. I would also like to thank Michael Cuffaro for helpful comments on an earlier draft.
References
- N. Bostrom, The Fable of the Dragon-Tyrant, J. Med. Ethics 31, 273 – 277 (2005), copy on author’s homepage.
- M. P. Müller, Law without law: from observer states to physics via algorithmic information theory, Quantum 4, 301 (2020).
- C. L. Jones and M. P. Müller, On the significance of Wigner’s Friend in contexts beyond quantum foundations, Quantum 10, 2147 (2026).
- G. M. D’Ariano and F. Faggin, Hard Problem and Free Will: An Information-Theoretical Approach, in Scardigli, F. (ed.), Artificial Intelligence Versus Natural Intelligence Springer, Cham, 2022; arXiv:2012.06580.
- P. Berghofer, Quantum Probabilities Are Objective Degrees of Epistemic Justification, arXiv:2410.19175.
- A. Chakravartty, Scientific Realism, The Stanford Encyclopedia of Philosophy (Summer 2017 Edition), Edward N. Zalta (ed.).
- A. Sokal and J. Bricmont, Fashionable Nonsense: Postmodern Intellectuals’ Abuse of Science, New York, Picador, 1999.
- L. Catani, M. Leifer, G. Scala, D. Schmid, and R. W. Spekkens, What is Nonclassical about Uncertainty Relations?, Phys. Rev. Lett. 129, 240401 (2022); arXiv:2207.11779.
- W. Wootters and W. Zurek, A Single Quantum Cannot be Cloned, Nature 299, 802–803 (1982).
- A. Peres, Quantum theory: concepts and methods, Kluwer Acad. Publ., Dordrecht, 2010.
- H. Everett, The Theory of the Universal Wave Function, 1956, in B. S. DeWitt and N. Graham (eds.), The Many-Worlds Interpretation of Quantum Mechanics, Princeton University Press, Princeton, 1973, Calisphere link.
- D. Dürr, S. Goldstein, T. Norsen, W. Struyve, and N. Zanghì, Can Bohmian mechanics be made relativistic?, Proc. R. Soc. A 470, 20130699 (2014); arXiv:1307.1714.
- G. Ghirardi and A. Bassi, Collapse Theories, The Stanford Encyclopedia of Philosophy (Fall 2024 Edition), E. N. Zalta & U. Nodelman (eds.).
- R. W. Spekkens, In defense of the epistemic view of quantum states: a toy theory, Phys. Rev. A 75, 032110 (2007); arXiv:quant-ph/0401052.
- L. Hausmann, A consolidating review of Spekkens’ toy theory, arXiv:2105.03277.
- L. Catani, M. Leifer, D. Schmid, R. W. Spekkens, Why interference phenomena do not capture the essence of quantum theory, Quantum 7, 1119 (2023).
- J. S. Bell, On the Einstein Podolsky Rosen paradox, Physics 1, 195 (1964).
- C. J. Wood and R. W. Spekkens, The lesson of causal discovery algorithms for quantum correlations: Causal explanations of Bell-inequality violations require fine-tuning, New J. Phys. 17, 033002 (2015).
- M. E. Cuffaro, The Measurement Problem Is a Feature, Not a Bug –Schematising the Observer and the Concept of an Open System on an Informational, or (Neo-)Bohrian, Approach, Entropy 25(10), 1410 (2023).
- R. Healey, Quantum Theory: a Pragmatist Approach, British J. Philos. Sci. 63(4), 729–771 (2012); arXiv:1008.3896.
- Č. Brukner and A. Zeilinger, Information and fundamental elements of the structure of quantum theory, in “Time, Quantum, Information”, edited by L. Castell and O. Ischebeck (Springer, 2003); arXiv:quant-ph/0212084.
- J. Bub, Bananaworld. Quantum Mechanics for Primates, Oxford University Press, Oxford, 2016.
- C. Rovelli, Relational quantum mechanics, Int. J. Theor. Phys. 35, 1637 (1996); arXiv:quant-ph/9609002.
- E. Adlam, Against Self-Location, Br. J. Phil. S, arXiv:2409.05259.
- F. A. Fuchs, Notwithstanding Bohr, the Reasons for QBism, Mind and Matter 15(2), 245-300 (2017); arXiv:1705.03483.
- S. M. Carroll, Why Boltzmann brains are bad, Current Controversies in Philosoph of Science, Routledge, 7–20 (2020); arXiv:1702.00850.
- A. Elga, Defeating Dr. Evil with self-locating belief, Philos. Phenomenol. Res. 69(2), 383–396 (2004); copy on author’s homepage.
- D. Parfit, Reasons and persons, Oxford University Press, Oxford (1984).
- P. Walley, Statistical Reasoning with Imprecise Probabilities, Monographs on Statistics and Applied Probability, Springer Science and Business Media, 1991.
- T. Fritz and M. Leifer, Plausibility measures on test spaces, arXiv:1505.01151.
- N. Friedman and J. Y. Halpern, Plausibility Measures: A User’s Guide, in P. Besnard and S. Hanks (eds.), Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence (UAI1995), Morgan Kauffman, 1995.
- D. Frauchiger and R. Renner, Quantum theory cannot consistently describe the use of itself, Nat. Commun. 9, 3711 (2018).
- J. Fankhauser, Epistemic Boundaries and Quantum Uncertainty: What Local Observers Can (Not) Predict, Quantum 8, 1518 (2024).
- J. Fankhauser, T. Gonda, and G. De les Coves, Epistemic Horizons From Deterministic Laws: Lessons From a Nomic Toy Theory, Synthese 205, 136 (2015); arXiv:2406.17581.
- J. Szangolies, Epistemic Horizons and the Foundations of Quantum Mechanics, Found. Phys. 48, 1669 (2018); arXiv:1805.10668.
- J. Barrett, L. Hardy, A. Kent, No signaling and quantum key distribution, Phys. Rev. Lett. 95, 010503 (2005); arXiv:quant-ph/0405101.
- R. Colbeck, Quantum and Relativistic Protocols For Secure Multi-Party Computation, PhD Thesis, University of Cambridge, 2006; arXiv:0911.3814.
- S. Pironio, A. Acín, S. Massar, A. Boyer de la Giroday, D. N. Matsukevich, P. Maunz, S. Olmschenk, D. Hayes, L. Luo, T. A. Manning and C. Monroe, Random numbers certified by Bell’s theorem, Nature 464, 1021 (2010); arXiv:0911.3427.
- J. B. DeBrota, C. A. Fuchs, and R. Schack, Respecting One’s Fellow: QBism’s Analysis of Wigner’s Friend, Found. Phys. 50, 1859–1874 (2020); arXiv:2008.03572.
- H. Zwirn, Are Events Absolute?, arXiv:2507.14672.
- D. C. Dennett, Real Patterns, J. Philos. 88(1), 27 (1991); download link at Rutgers Center for Cognitive Science.
- H. Kragh, The first curved-space universe, Astron. Geophys. 53(5), 5.13–5.15 (2012).
- T. M. Cover and J. A. Thomas, Elements of Information Theory, John Wiley & Sons, 2006.
- M. Hutter, Universal Artificial Intelligence – Sequential Decisions Based on Algorithmic Probability, Springer, Berlin, Heidelberg, 2005.
- M. Li and P. Vitányi, Kolmogorov Complexity and Its Applications, 3rd Edition, Springer, 2008.
- D. Deutsch, Quantum theory, the Church-Turing principle and the universal quantum computer, Proc. R. Soc. (London) A 400, 97–117 (1985); download link.
- S. Wolfram, A New Kind of Science, Champaign, Illinois, 2002.
- R. Gandy, Church’s thesis and principles for mechanisms, Stud. Log. Found. Math. 101, 123-148 (1980); download link.
- P. Arrighi and G. Dowek, The physical Church-Turing thesis and the principles of quantum theory, Int. J. Found. Comput. S. 23(5), 1131–1145 (2012); arXiv:1102.1612.
- D. R. Hofstadter, Gödel, Escher, Bach: an eternal golden braid, Basic Books, New York, 1979.
- G. Piccinini, Computationalism, The Church-Turing Thesis, and the Church-Turing Fallacy, Synthese 154(1), 97–120 (2007); JSTOR download.
- N. Bostrom, Superintelligence: Paths, Dangers, Strategies, Oxford University Press, Oxford, 2014.
- D. C. Dennett, Freedom Evolves, Penguin Group, New York, 2003.
- G. Egan, Permutation City, Night Shade Books, 2014.
- D. Chalmers, Reality+. Virtual Worlds and the Problems of Philosophy, W. W. Norton, 2022.
- E. Schwitzgebel, Let’s Hope We’re Not Living in a Simulation, Philos. Phenomenol. Res. 109, 1042-1048 (2024); download preprint.
- B. Coecke and A. Kissinger, Picturing Quantum Processes, Cambridge University Press, Cambridge, 2017.
- K.-W. Bong, A. Utreras-Alarcón, F. Gharafi, Y.-C. Liang, N. Tischler, E. G. Cavalcanti, G. J. Pryde, and H. M. Wiseman, A strong no-go theorem on the Wigner’s friend paradox, Nat. Phys. 16, 1199–1205 (2020).
- E. P. Wigner, Remarks on the Mind-Body Question, in Symmetries and Reflections, 171–184, Indiana University Press, Bloomington, Indiana, 1967; download link.
- N. Block, Troubles with functionalism, in C. W. Savage (ed.), Perception and cognition: issues in the foundations of psychology, University of Minnesota Press, Minneapolis, 1978.; download link.
- J. Schmidhuber, Algorithmic Theories of Everything, Instituto Dalle Molle Di Studi Sull Intelligenza Artificiale (2000), arXiv:quant-ph/0011122.
- S. Lloyd, Programming the Universe: A Quantum Computer Scientist Takes on the Cosmos, Random House, New York, 2006.
- D. Lewis, On the Plurality of Worlds, Wiley-Blackwell, 2001.
- N. Bostrom, Are We Living in a Computer Simulation?, Philos. Q. 53(211), 243–255 (2003); copy on JSTOR.
- T. Ord, The Precipice. Existential Risk and the Future of Humanity, Bloomsbury Publishing, 2020.
- A. Fine, Hidden Variables, Joint Probability, and the Bell Inequalities, Phys. Rev. Lett. 48, 291 (1982); copy on author’s homepage.
- M. P. Müller, Probabilistic theories and reconstructions of quantum theory, SciPost Phys. Lect. Notes 28 (2021).
- L. Hardy, Quantum theory from five reasonable axioms, arXiv:quant-ph/0101012 (2001).
- B. Dakić and Č. Brukner, Quantum theory and beyond: is entanglement special?, in Deep Beauty: Understanding the Quantum World through Mathematical Innovation (ed. H. Halvorson), Cambridge University Press, Cambridge, 2011; arXiv:0911.0695.
- L. Masanes and M. P. Müller, A derivation of quantum theory from physical requirements, New J. Phys. 13, 063001 (2011); arXiv:1004.1483.
- G. Chiribella, G. M. D’Ariano, and P. Perinotti, Informational derivation of quantum theory, Phys. Rev. A 84, 012311 (2011); arXiv:1011.6451.
- J. Barrett, N. Linden, S. Massar, S. Pironio, S. Popescu, and D. Roberts, Nonlocal correlations as an information-theoretic resource, Phys. Rev. A 71, 022101 (2005); arXiv:quant-ph/0404097.
- H. Price, Bell correlations and selection bias, arxiv:2605.00406.
- S. Aaronson, NP-complete problems and physical reality, ACM SIGACT News 36(1), 30–52 (2005); arXiv:quant-ph/0502072.
- K. Zuse, Rechnender Raum, Friedrich Vieweg u. Sohn, Wiesbaden, 1969; download link.
Version 1.3 of July 2, 2026